数据同步 Schema Evolution
场景描述
在数据库应用领域,对于表结构的定义往往在应用上线前就已经定义好,包括表的 DDL 、索引创建和约束检查等。但随着业务的飞速发展,我们经常会面临对已有的表结构或者索引字段等进行一些变更的需求。在业务上线后,伴随着持续的读写流量,如何高效的能支持这类变更需求成为一个常见问题。传统的解法往往需要暂停业务的读写,获取一个升级窗口来进行表结构的变更等操作。在 ProtonBase 中,我们通过对 Schema Evolution 的高效支持,来解决此类问题。
Schema Evolution,全称为模式演化。是指随着新需求和数据模型的出现,跟随时间的推移修改数据库模式结构的过程。它涉及更改模式以适应新的数据元素或对现有数据元素的更改,同时保持数据的完整性和一致性。在我们本文讨论的范畴中,主要涉及以下场景:
- 在数据同步产品进行增量数据同步的过程中上游数据源端出现的表结构变更,比如新建表、表中新加字段、修改字段类型等,会自动将新的表结构同步到 ProtonBase 对于 Schema Evolution 的支持,对于不同的源端数据产品有不同的方式:
- 半结构化的数据产品,比如 MongoDB 。数据的存储是一个 JSON ,不存在 DDL ,但是 JSON 的键值可能发生变化
- 结构化的关系型数据库,通过某些方式拿到 DDL 变更,在目标端直接 Apply 变更,比如 MYSQL、PostgreSQL、SqlServer 和 Oracle 等
对于 MongoDB , ProtonBase 数据同步产品开放了前端配置能力,可以让用户指定 Schema 结构。如果遇到初始 Schema 以外的字段, ProtonBase 数据同步产品会放到 Extra 字段来支持后续的 JSON 数据中出现的键值更新。
对于结构化的关系型数据库,ProtonBase 数据同步产品的 Schema Evolution 底层实现机制基本一致。但是 DDL 变更的捕获方式不同。 对 MySQL、SqlServer和 Oracle 等的源端,增量消息中直接会有 DDL 变更。ProtonBase 数据同步产品将 DDL 变更进行 SQL 解析后在目标端 ProtonBase 执行对应 DDL 操作就可以。对于 PostgreSQL 的的数据源,目前的复制机制里没有直接同步 DDL 的变更,捕获 DDL 变更比较复杂。因此本文以 PostgreSQL 的源端如何支持在数据增量同步过程中的 Schema Evolution 为例进行后续讲解。
PG 生态下的源端数据同步,通过 CDC 来实现。CDC,全称 Change Data Capture,是一种观察写入数据库的所有变更,并将其转换为可以复制到其他系统中的形式的过程。ProtonBase 数据同步产品使用逻辑复制来订阅上游的变更操作。逻辑复制是一种高级的复制技术,它可以在不同的 PostgreSQL 数据库之间同步数据,甚至可以跨版本同步数据。与传统的流复制(streaming replication)相比,逻辑复制可以更加灵活地选择需要复制的表和列,也可以过滤掉不需要复制的数据。此外,逻辑复制可以在主库上执行数据转换和过滤操作,这对于一些特殊需求非常有用,例如数据仓库和实时数据分析等。逻辑复制的增量消息解析使用 pgoutput 插件。 标准的逻辑解码输出插件。它由 PostgreSQL 社区维护,并由 PostgreSQL 本身用于逻辑复制。该插件始终存在,因此无需安装额外的库。
在基于逻辑复制进行DDL变更识别时,有两种常见做法,一种是通过触发器和函数来实现,通过在源端配置触发器来捕获表的DDL变更并且单独记录到一个表来识别所有的 Schema Evolution 操作。另一种方式是通过 Relation Message 来捕获 DDL 变更,变更后的该表的第一个 DML 前面会发一条 Relation Message 。对于常见的一些表结构变更,比如加列、减列、新建表、重命名列等,均会发出 Relation Message。
对于 ProtonBase 而言,使用 ProtonBase 数据同步产品同步数据的时候往往对应如下场景:
- 一次性将源端数据同步到ProtonBase,然后基于此份快照数据进行POC验证
- 将生产库的全量 + 增量数据同步到 ProtonBase,ProtonBase作为一个只读备实例存在,方便业务上进行 A/B Test
如果采用第一种 Schema Evolution 的实现,用户需要对每一个 Database 进行触发器和函数的流程创建,相对繁琐。基于这个原因,ProtonBase 数据同步产品采用 Relation Message 的方式来实现 Schema Evolution。
源端设置
以下设置为进行PG逻辑订阅的必须条件,是PG自身逻辑复制机制的需求。实际在使用其他一些类似同步工具的时候也同样要有这些设置的要求。
- 设置 wal_level 为 logical。wal_level 有三种级别:minimal、replica 和 logical。minimal 记录的 WAL 日志信息最少,只包含了数据库异常关闭需要恢复时的基本 WAL 信息; logical 记录的WAL日志信息最多,包含了支持逻辑解析所需的WAL。replica记录的 WAL 信息介于二者之间。只有开启 logical 级别的 WAL 日志信息采集,才会记录 Relation Message。通过如下命令进行设置:
ALTER SYSTEM SET wal_level TO 'logical';- 表被 publication 订阅
- 方式一:一开始订阅全部的表
CREATE PUBLICATION xx_pub FOR ALL TABLES;- 方式二:用户建好表后,在新表写入数据前,修改订阅
ALTER PUBLICATION publication_name ADD TABLE table_name;- 需要同步的表必须有主键。如果是无主键表(包括只有唯一键但没有主键的表),需要将 replica identity 设置为 full 模式,否则会导致源端PG库无法做 update 和 delete 。建议将所有表设置为有主键表。
alter table t replica identity full;DDL变更检测
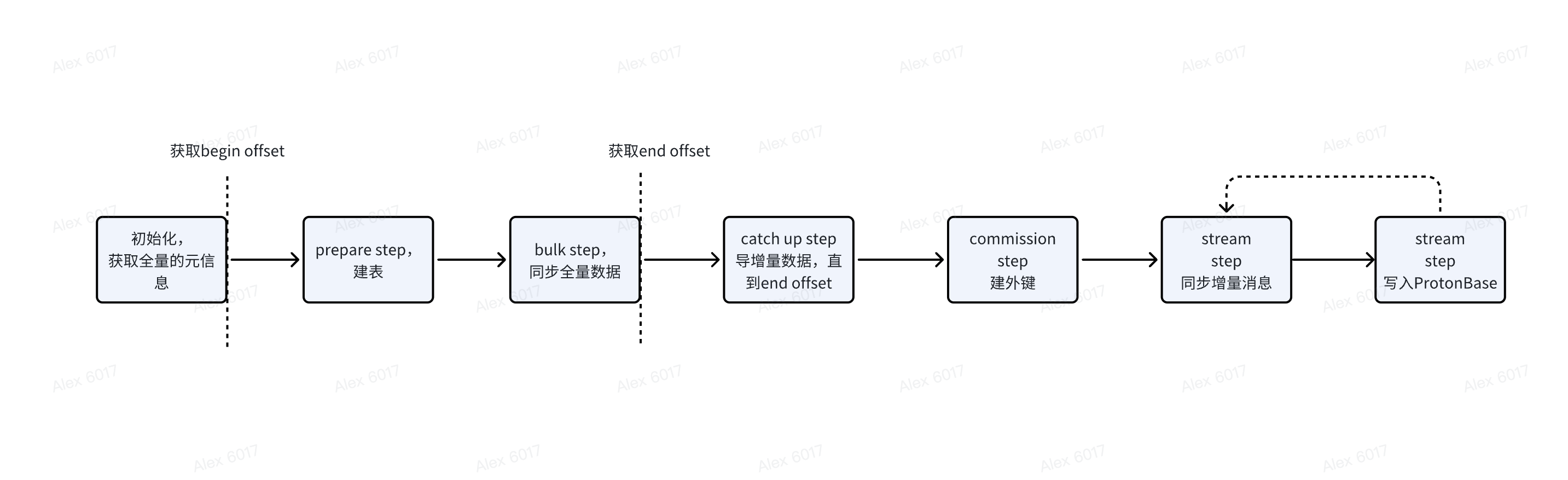 上图是ProtonBase 数据同步产品的整个导数据的流程。在没有 Schema Evolution 之前初始化获取全量信息时,直接读取源端的数据库的元信息来建表即可,不需要记录任何状态。
支持Schema Eovoluiton后,需要在第一次获取表 meta 信息的 snapshot,并记录状态。并在后续发生 DDL 变更时,将变更也落入状态中。对于 ProtonBase 数据同步产品而言,slice 是内部资源调度的最小单位,一个 slice 负责启动一个同步若干条数据的任务。PG的数据同步按照 Database 粒度进行,一个 DataBase 的同步会对应一个流。
ProtonBase 数据同步产品 Schema Evolution 的基本流程如下:
上图是ProtonBase 数据同步产品的整个导数据的流程。在没有 Schema Evolution 之前初始化获取全量信息时,直接读取源端的数据库的元信息来建表即可,不需要记录任何状态。
支持Schema Eovoluiton后,需要在第一次获取表 meta 信息的 snapshot,并记录状态。并在后续发生 DDL 变更时,将变更也落入状态中。对于 ProtonBase 数据同步产品而言,slice 是内部资源调度的最小单位,一个 slice 负责启动一个同步若干条数据的任务。PG的数据同步按照 Database 粒度进行,一个 DataBase 的同步会对应一个流。
ProtonBase 数据同步产品 Schema Evolution 的基本流程如下:
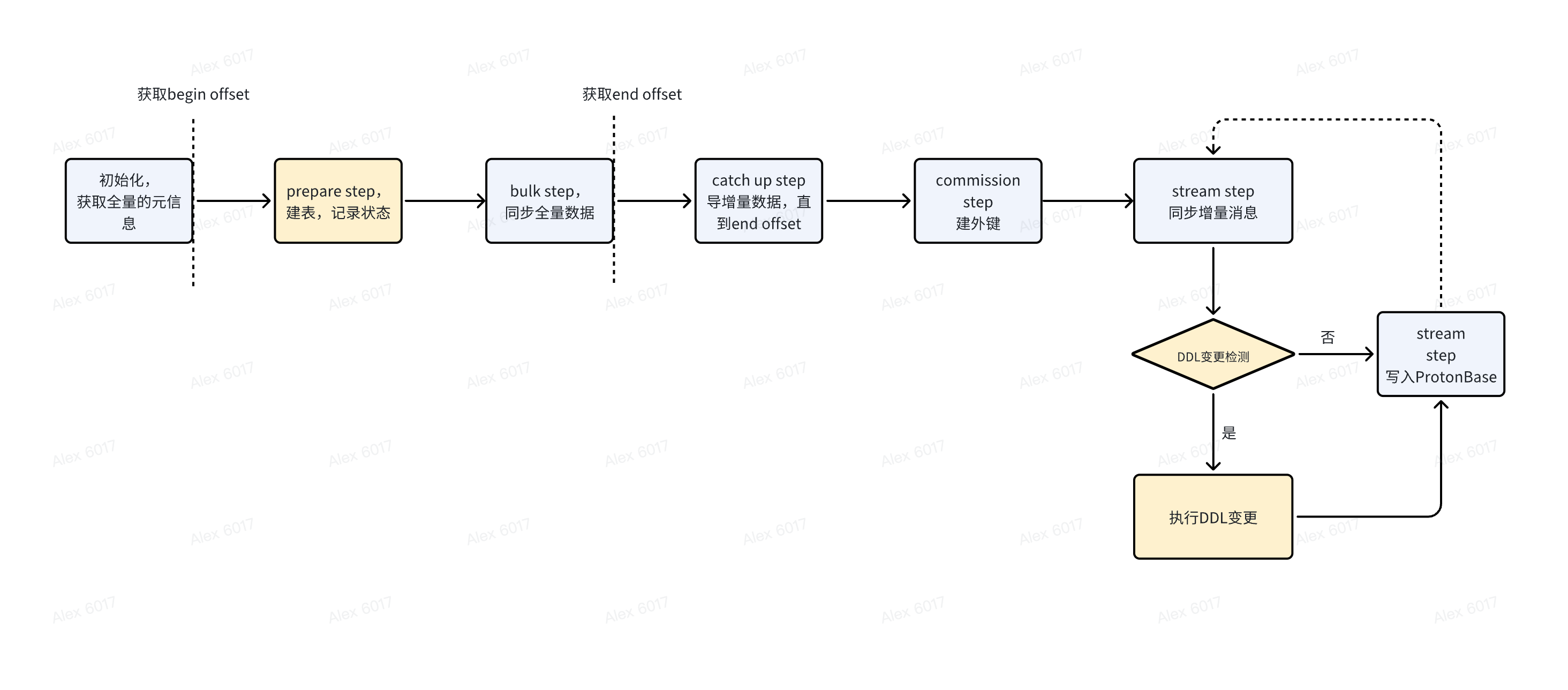
- 第一次启动,先按流的个数分 slice,并将 slice 的id记录状态。因为各 slice 的启动位点、消费进度可能都有差别,所以没法记录统一的状态
- 每个 slice,获取对应的Meta信息,并且记录 snapshot 状态
- 内部source connector通过 Relation Message 检测源端是否发生 DDL 变更。对于 PostgreSQL,在 Relation 消息中比较下消息中的列名、列类型和当前Meta信息中的差异,有差异会在目标端 ProtonBase 执行相应变更且将状态记录到新版本。
能力描述
目前 ProtonBase 数据同步产品支持在线的对源端的表的 DDL 变更操作的自动同步,比如新建表、新建列、删除列和更改列数据类型等常见的操作,一般在秒级可以完成。对于遇到的不支持的异常变更操作,ProtonBase 数据同步产品也会有自我保护机制,中断个别表的同步保持整个数据增量同步流程持续进行。除此之外,相比市面上的其他同步工具 ProtonBase 数据同步产品还额外做了诸多优化。
TimeTravel 能力支持
ProtonBase 数据同步产品通过识别Relation消息的变更生成不同位点的元信息,并且记录到状态表。如果客户想从某个位点重新追增量,ProtonBas e数据同步产品可以从状态表中获取到当时位点对应的元信息,这样就可以支持从任意点位进行增量数据的回放。 以如下表为例,我们讲解下 ProtonBase 数据同步产品 TimeTravel 的能力。
CREATE TABLE COMPANY(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);为方便理解,下面落入状态表的信息均按照\d展示的表结构讲解,不按照实际的存储信息展示。 全量同步开始T0时刻,落入状态表表的 Schema 定义如下:
protonbase=> \d COMPANY
Table "public.company"
Column | Type | Collation | Nullable | Default
---------+---------------+-----------+----------+---------
id | integer | | not null |
name | text | | not null |
age | integer | | not null |
address | character(50) | | |
salary | real | | |
Indexes:
"company_pkey" PRIMARY KEY, btree (id ASC)T1时刻同步完所有全量 + 追完同步全量期间的增量后,开始进行实时增量同步。 T2时刻遇到加列的Schema Evolution,加了一个新列 department ,新的表定义如下,落入状态表并且更新Version。
protonbase=> \d COMPANY
Table "public.company"
Column | Type | Collation | Nullable | Default
------------+---------------+-----------+----------+---------
id | integer | | not null |
name | text | | not null |
age | integer | | not null |
address | character(50) | | |
salary | real | | |
department | text | | |
Indexes:
"company_pkey" PRIMARY KEY, btree (id ASC)
T3时刻遇到修改字段类型的Schema Evolution,age字段从INT变为BIGINT,新的表定义如下,落入状态表并且更新Version。
protonbase=> \d COMPANY
Table "public.company"
Column | Type | Collation | Nullable | Default
------------+---------------+-----------+----------+---------
id | integer | | not null |
name | text | | not null |
age | bigint | | not null |
address | character(50) | | |
salary | real | | |
department | text | | |
Indexes:
"company_pkey" PRIMARY KEY, btree (id ASC)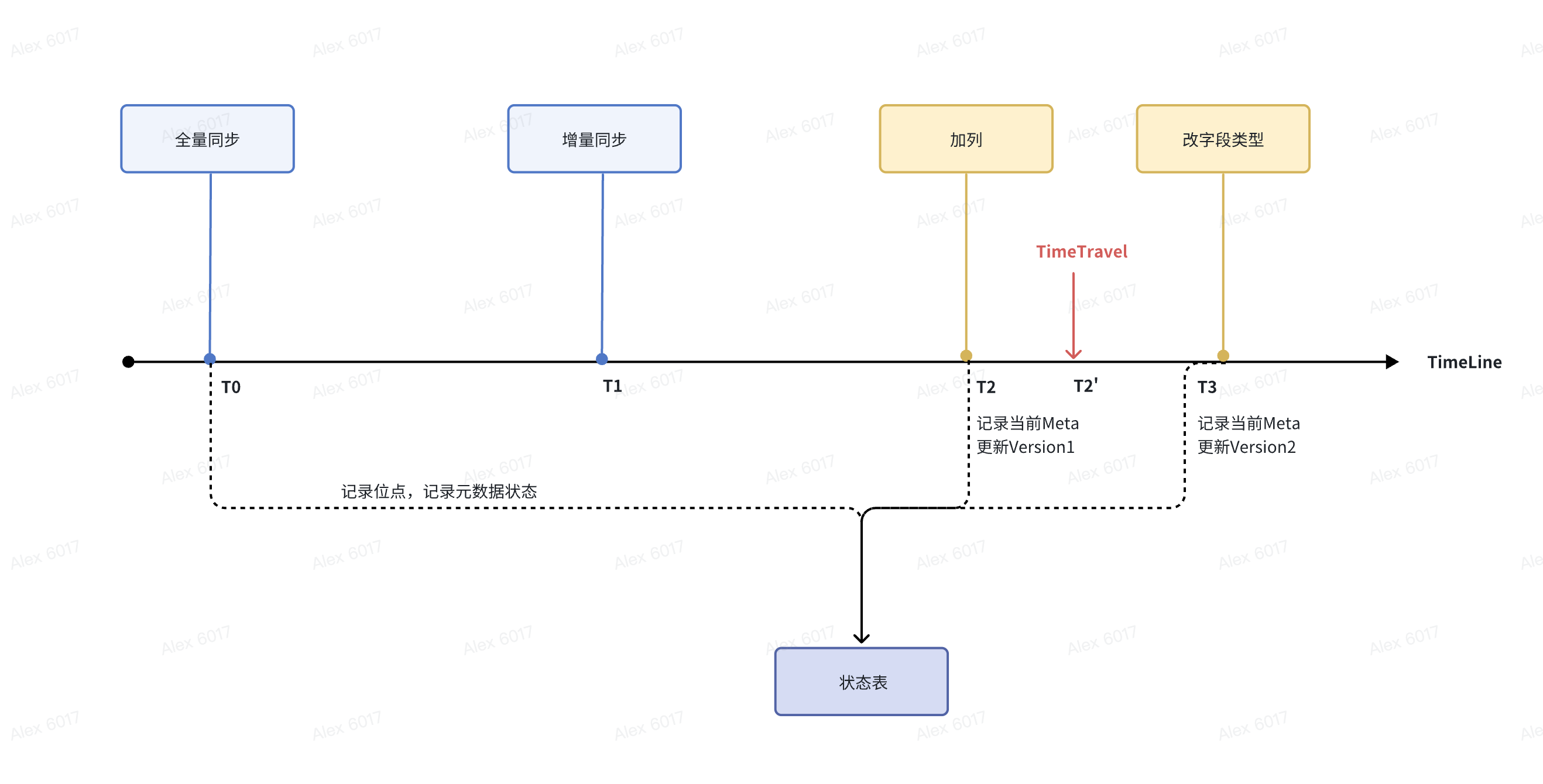 如果因为某些原因,客户想从 T2' 时刻开始开始重追增量的时候,在[T2’, T3]这个时间区间,ProtonBase数据同步产品会从状态表中获取最相近的一个时刻T2的元信息,对增量消息按那个时刻的结构来进行解析。通过类似的方式, ProtonBase 数据同步产品可以支持TimeTravel的功能,从指定的任意时刻(位点)开始追增量并且还原到当时的元信息就行增量消息解析。
如果因为某些原因,客户想从 T2' 时刻开始开始重追增量的时候,在[T2’, T3]这个时间区间,ProtonBase数据同步产品会从状态表中获取最相近的一个时刻T2的元信息,对增量消息按那个时刻的结构来进行解析。通过类似的方式, ProtonBase 数据同步产品可以支持TimeTravel的功能,从指定的任意时刻(位点)开始追增量并且还原到当时的元信息就行增量消息解析。
事务与事务交叉支持
目前常见的数据同步工具,都不保证增量数据同步过程中的事务,只保证了最终一致性。ProtonBase 数据同步产品在实现的时候,按照源端的操作顺序,也保持了对事务的支持,从而保证了同步过程中和源端数据的严格一致性。同时,对于过程中出现了事务交叉的场景, ProtonBase 数据同步产品也进行了针对性处理来解决这种场景容易出现的一致性问题。 比如如下场景:
begin; -- 事务1
insert into t1 (id, name) values(1, 'a'); -- 事务1
alter t1 add column age int; -- 事务1,修改表1的元数据,添加了age字段
insert into t1 (id, name, age) values(2, 'b', 10); -- 事务1;
begin; -- 事务2
insert into t2 (id, name) values(1, 'a'); -- 事务2
alter t2 add column age int; -- 事务2,修改表2的元数据,添加了age字段
commit; -- 事务2
begin; --事务3
insert into t1 (id, name) values(10, 'b'); --事务3,应该看到事务1之前的t1表结构
commit; --事务3
insert into t1 (id, name, age) values(3, 'c', 11); -- 事务1
rollback; -- 事务1
begin; --事务4
insert into t1 (id, name) values(2, 'b'); --事务4,应该看到事务1之前的t1表结构
commit; --事务4如上所示,是多个并发操作的事务最后记录在数据库中的 wal log 中的顺序。如果在同步的时候有元数据同步技术未支持事务的话,当执行了t1表的变更后,t1表的变更即对其它事务均可见,后续事务1的回滚操作也未执行。会导致与预期的语义不符。
相似结构多表到同表的导入
为了解决分库分表的数据导入 ProtonBase 的问题,ProtonBase数据同步产品支持按照基于规则的前缀匹配,来将多个拆分后的表同步到同一个 ProtonBase 的表里。随着业务的发展,在后续新分出的表中,可能会比之前的表有更多的列, ProtonBase 数据同步产品也会通过合并所有表中的列,打成大宽表的方式支持所有源表的同步。除了一次性的同步,ProtonBase 数据同步产品对后续新建的满足表名匹配规则的表也会进行增量同步,更好的满足业务需求。通过该机制,可以很容易的将分库分表的业务表导入到 ProtonBase 。 语法示例如下:
case
when ${expression} like ${expression} then ${expression}
when regexp_match(${expression}, ${regex}) like then ${expression}
...
when ${condition} then ${expression}
else ${expression}
end其中 regex 为标准正则表达方式,支持将 () 内的数据作为分组提取出来,提取的变量名为 $1, $2,......, $n,可以用于 expression 表达式。 例子:将源端 t1_000,t1_001,......,t1_009 映射到目标端 t1,将源端 t2_000,t2_001,......,t2_009 映射到目标端 t2 通过 like 配置分表映射。
case
when SOURCE_OBJECT like 't1_%' then concat(SOURCE_DATABASE, '.public.t1')
when SOURCE_OBJECT like 't2_%' then concat(SOURCE_DATABASE, '.public.t2')
else concat(SOURCE_DATABASE, '.', 'public', '.', SOURCE_OBJECT)
end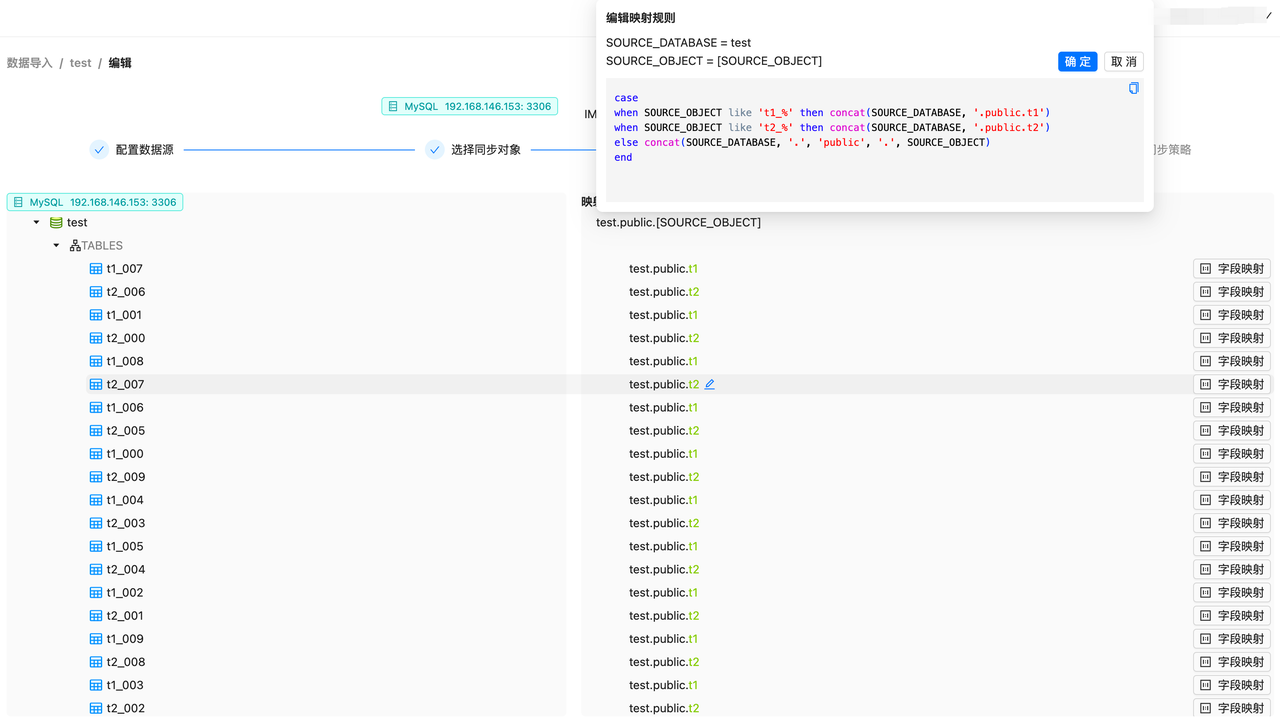
实例级别 Schema Evolution
不同于其他同步工具一次只能同步一个DB的配置方式,ProtonBase数据同步产品一次配置同步,可以将整个实例的数据进行同步并且同时支持多库 Schema Evolution。配合前端 UI 的简易操作,用户可以很容易的按需对整个实例数据或者部分表进行同步。
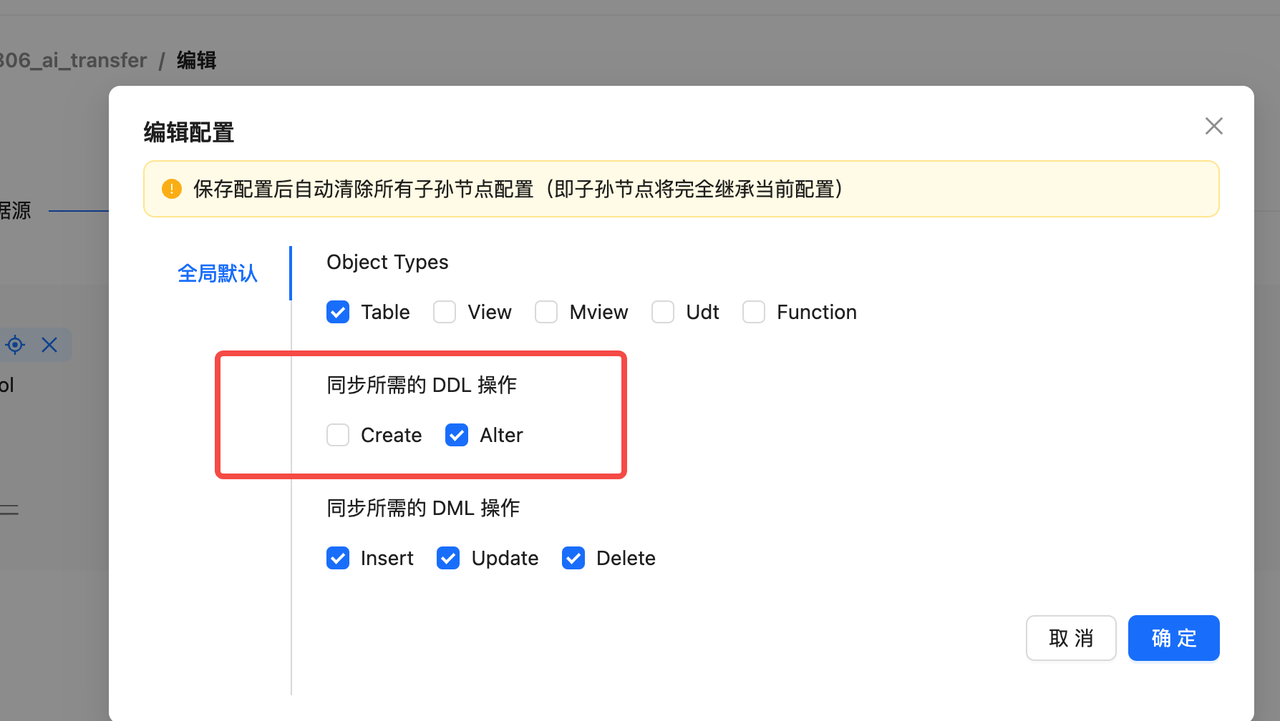
灵活开关 Schema Evolution
ProtonBase数据同步产品默认开启了Schema Evolution的能力。在开始数据同步前,通过ProtonBase产品的控制台页面,用户可以很容易的对数据库进行 Schema Evolution 能力的开启/关闭。如果对已经在持续增量订阅的数据同步任务进行变更,需要先暂停同步任务,修改配置后重新点击"恢复"按钮启动任务即可生效。
后续规划
Schema Evolution 由于其场景复杂性,想做的比较完备注定会是一个长期工作。ProtonBase会在这方面进行持续的优化。后续会从以下方面来进一步加强:
- 存储模式的变更支持。比如一开始的存储格式是列存,但是后续的业务中又出现了高并发的 Serving 查询,需要能在线的比较高效的将数据存储模式变为行列混存
- ProtonBase数据同步产品对于一些高级特性的 Schema Evolution 的支持。比如触发器、视图等