从 AWS Redshift 迁移到 ProtonBase 指南
前提条件
-
需要有权限访问AWS的Redshift及S3环境。
-
对于目标端,需要有目标端云服务的对象存储的权限(如阿里云的OSS,AWS的S3等)这里以阿里云OSS为例。这里以同AWS区域为例,从宁夏(中国)的Redshift迁移到宁夏(中国)的ProtonBase。
背景信息
将Amazon Redshift数据迁移至ProtonBase的流程如下。
- 将Amazon Redshift数据导出至Amazon S3数据湖(简称S3)。
- 将数据从S3迁移至同区域的ProtonBase项目中,并校验数据完整性和正确性。
说明
由于Amazon Redshift和ProtonBase之间语法存在很多差异,因此在实际迁移过程中,您需要修改Amazon Redshift上编写的脚本,然后才能在ProtonBase中使用。由于ProtonBase兼容Postgresql 的语法,可以参考Amazon Redshift和Postgresql间的语法差异信息,请参见Amazon Redshift 和 PostgreSQL - Amazon Redshift (opens in a new tab)
步骤一:将Amazon Redshift数据导出至S3
Amazon Redshift支持IAM角色和临时安全凭证(AccessKey)认证方式。您可以基于这两种认证方式通过Redshift UNLOAD命令将数据导出至S3。将Amazon Redshift数据导出至S3的详细操作内容请参见卸载数据 (opens in a new tab)。
两种认证方式的UNLOAD命令格式如下:
- 基于IAM角色的UNLOAD命令
-- 通过UNLOAD命令将表customer的内容导出至S3。
UNLOAD ('SELECT * FROM customer')
TO 's3://bucket_name/unload_from_redshift/customer/customer_' --S3 Bucket。
IAM_ROLE 'arn:aws-cn:iam::****:role/MyRedshiftRole'; --角色ARN。- 基于AccessKey的UNLOAD命令
-- 通过UNLOAD命令将表customer的内容导出至S3。
UNLOAD ('SELECT * FROM customer')
TO 's3://bucket_name/unload_from_redshift/customer/customer_' --S3 Bucket。
Access_Key_id '<access-key-id>' --IAM用户的Access Key ID。
Secret_Access_Key '<secret-access-key>' --IAM用户的Access Key Secret。
Session_Token '<temporary-token>'; --IAM用户的临时访问令牌。UNLOAD命令导出的数据格式如下:
- 以PARQUET格式导出,便于其它引擎直接读取数据。命令示例如下。
UNLOAD ('SELECT * FROM customer')
TO 's3://bucket_name/unload_from_redshift/customer_parquet/customer_'
FORMAT AS PARQUET
IAM_ROLE 'arn:aws-cn:iam::xxxx:role/redshift_s3_role';- 执行成功后,您可以在对应Bucket中查看导出的文件。PARQUET文件数据压缩率更高,查询速度更快。
本文以IAM角色认证及导出PARQUET格式为例介绍数据迁移操作。
-
新建Redshift类型的IAM角色。
-
登录IAM控制台 (opens in a new tab),单击创建角色。
-
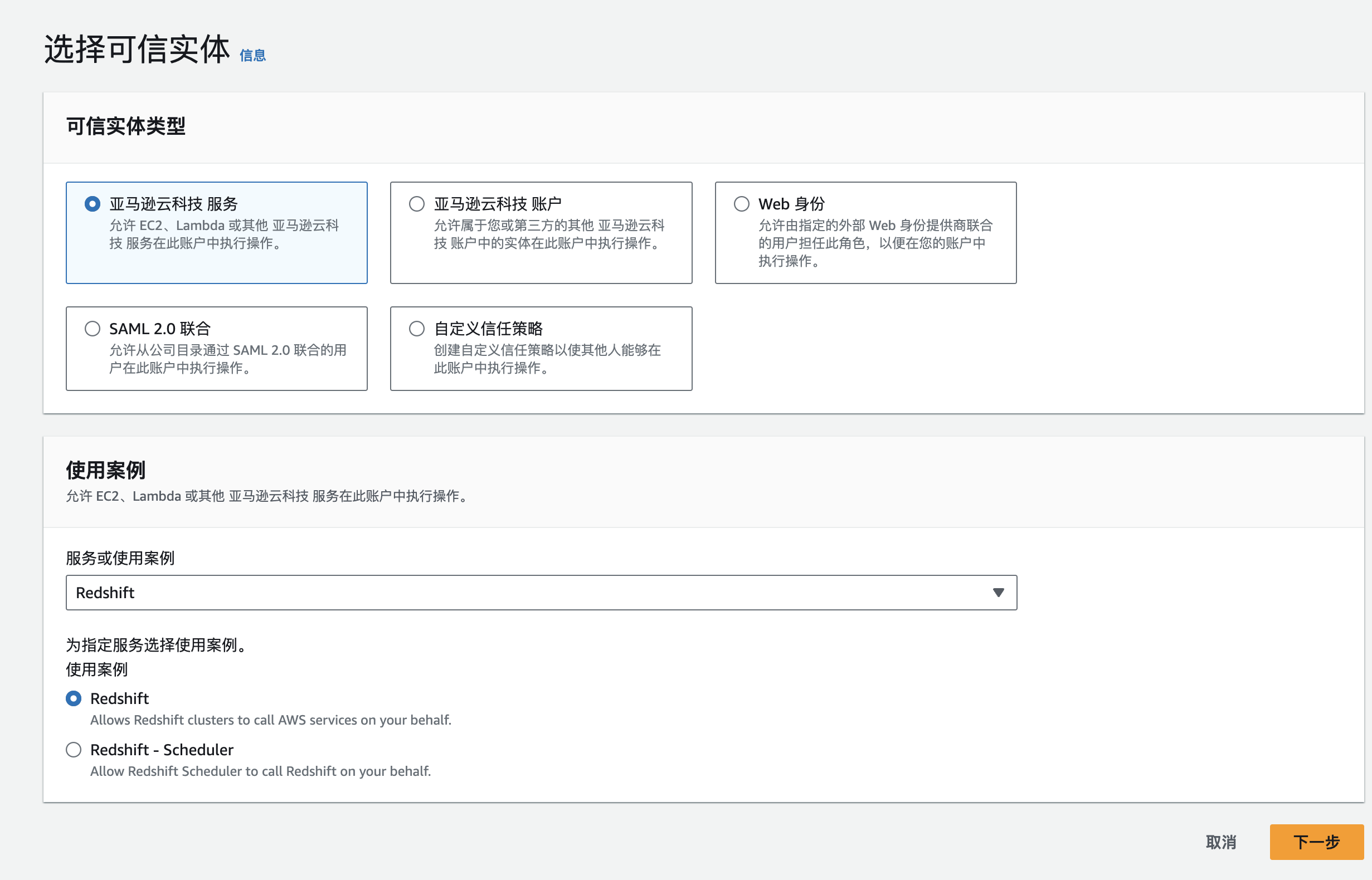
在创建角色页面的选择“亚马逊云科技 服务”,使用案例选择“Redshift”。在选择您的使用案例区域单击Redshift后,单击下一步。
-
-
添加读写S3的权限策略。在创建角色页面的Attach权限策略区域,输入S3,选中AmazonS3FullAccess,单击下一步。
-
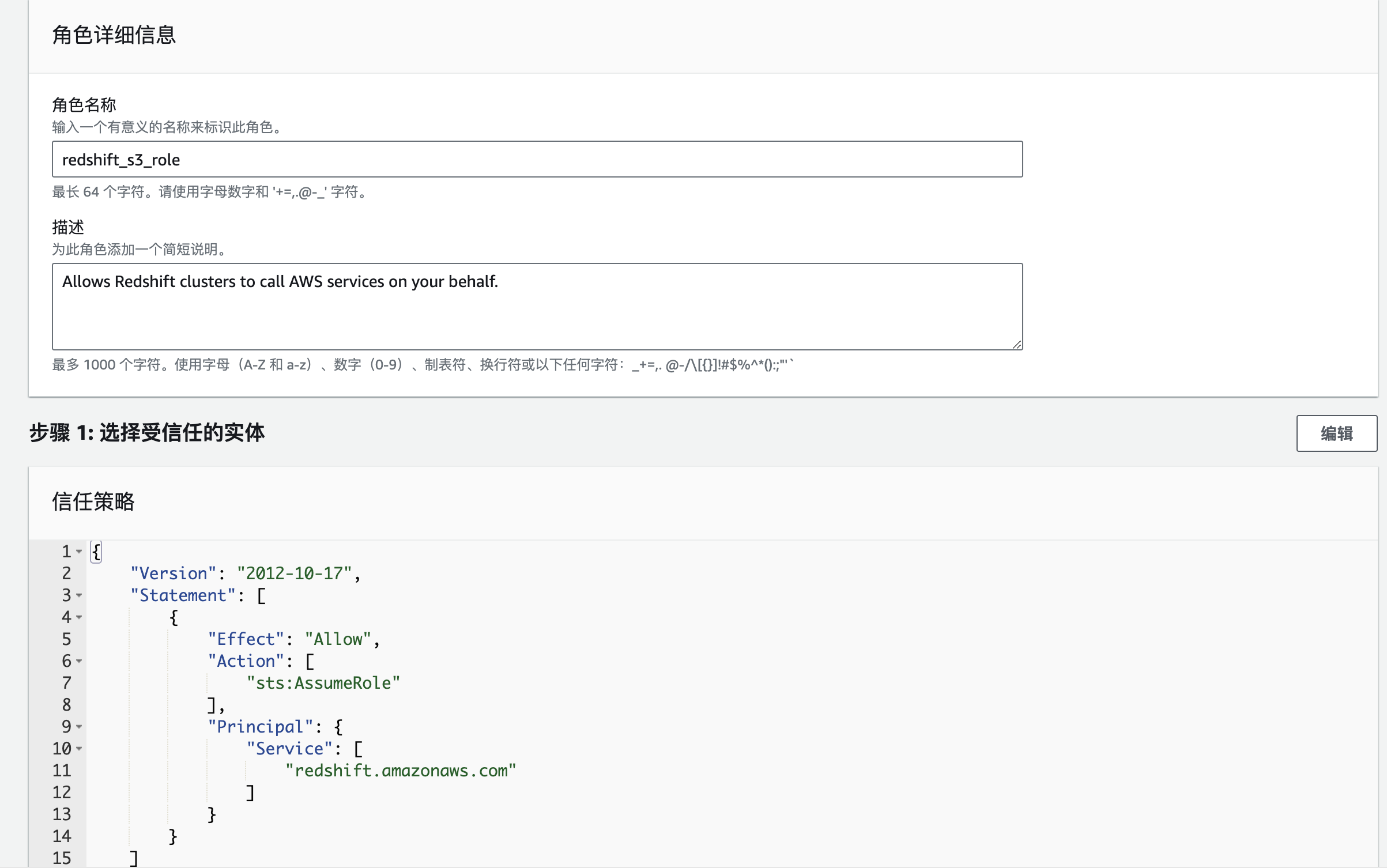
为IAM角色命名并完成IAM角色创建。
- 单击下一步:审核,在创建角色页面的审核区域,配置角色名称和角色描述,单击创建角色,完成IAM角色创建。
-
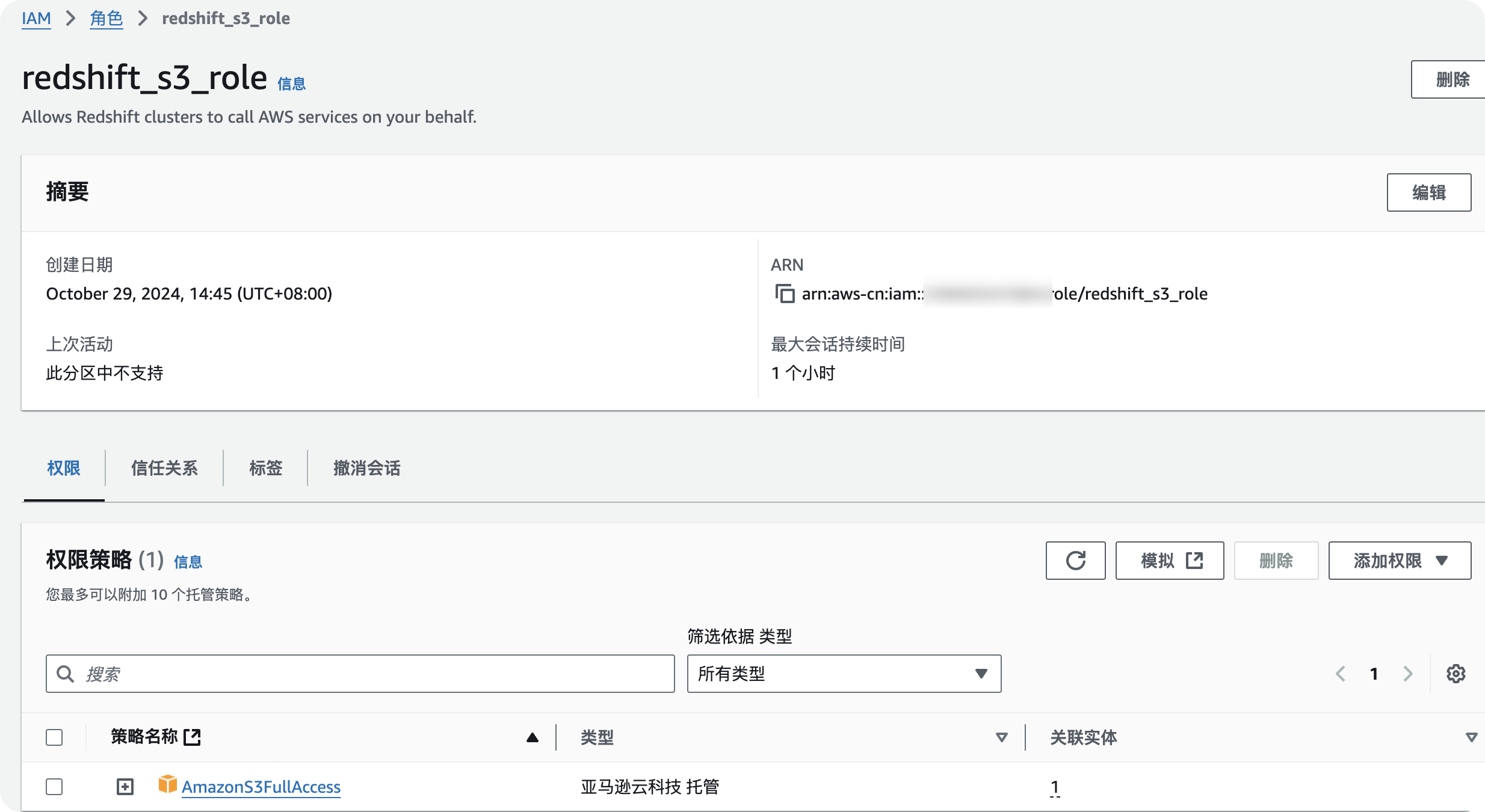
返回IAM控制台 (opens in a new tab),在搜索框输入redshift_s3_role,单击redshift_s3_role角色名称,获取并记录角色ARN。
-
执行UNLOAD命令迁移数据时会使用角色ARN访问S3。
-
为Redshift集群添加创建好的IAM角色,获取访问S3的权限。
-
登录Amazon Redshift控制台 (opens in a new tab),在右上角选择区域为中国 (宁夏)。
-
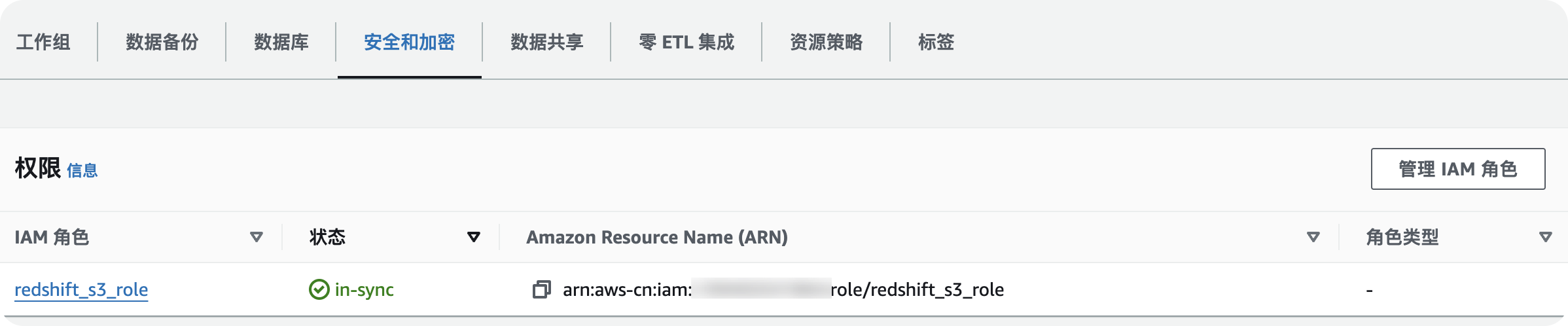
在左侧导航栏,单击集群,选中已创建好的Redshift集群,在操作下拉列表选择管理 IAM 角色。
-
在管理 IAM 角色页面,单击搜索框右侧的
-
图标,选择redshift_s3_role。单击添加 IAM 角色 > 完成,将具备S3访问权限的redshift_s3_role添加至Redshift集群。
-
-
将Amazon Redshift数据导出至S3。
-
在左侧导航栏,单击编辑器,执行UNLOAD命令将Amazon Redshift数据以PARQUET格式导出至S3的Bucket目录。
-
命令示例如下。
UNLOAD ('SELECT * FROM tickit.category')
TO 's3://bucket_name/unload_from_redshift/customer_parquet/category_'
FORMAT AS PARQUET
IAM_ROLE 'arn:aws-cn:iam::xxxx:role/redshift_s3_role';
UNLOAD ('SELECT * FROM tickit.date')
TO 's3://bucket_name/unload_from_redshift/orders_parquet/date_'
FORMAT AS PARQUET
IAM_ROLE 'arn:aws-cn:iam::xxxx:role/redshift_s3_role';-
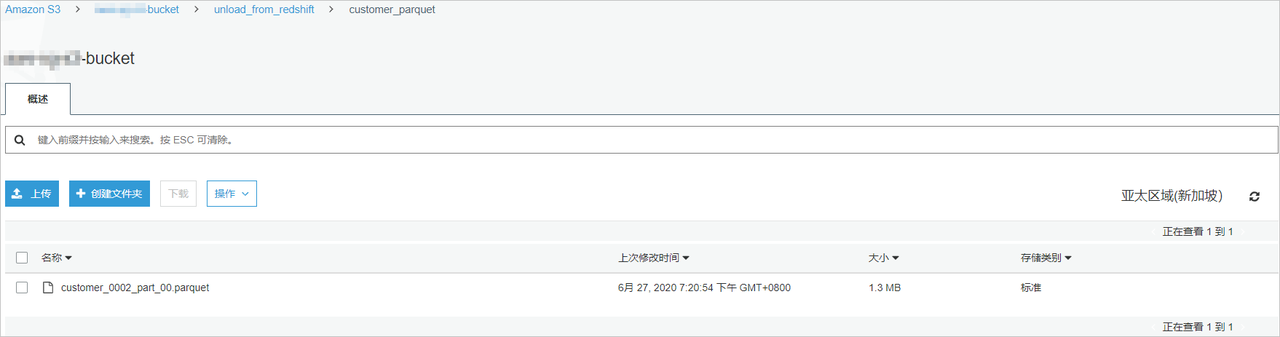
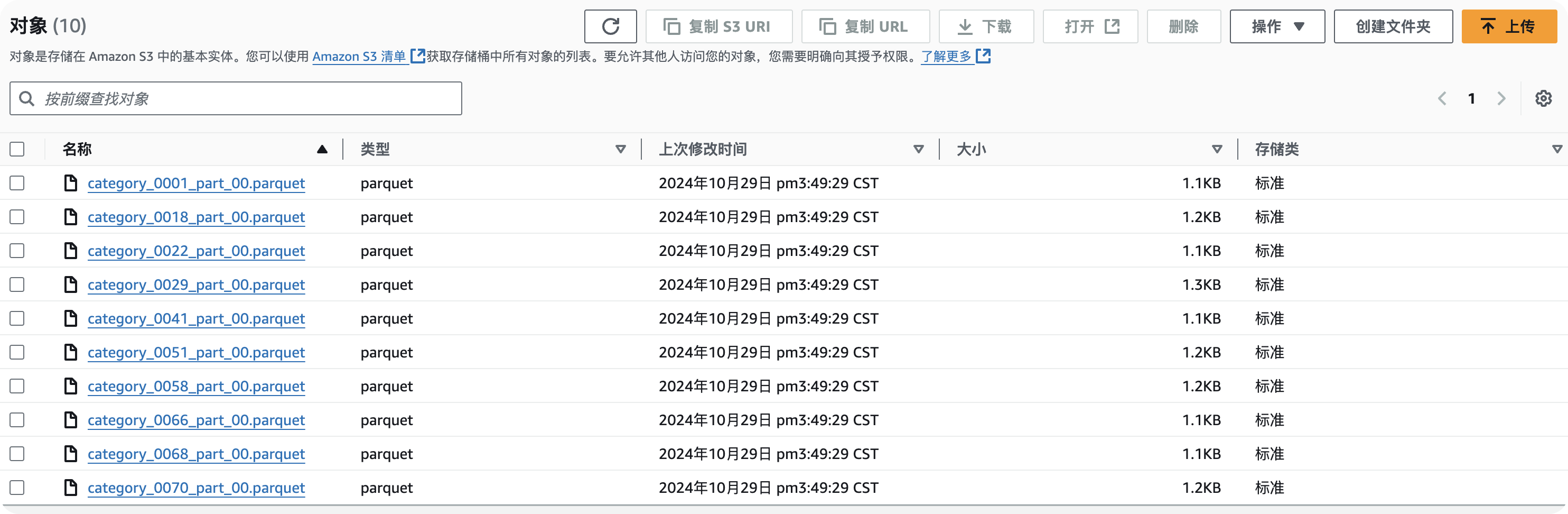
登录S3控制台 (opens in a new tab),在S3的Bucket目录下检查导出的数据。
格式为符合预期的PARQUET格式。

步骤二:将数据从S3迁移至同区域的 Protonbase
您可以通过 ProtonBase 的create foreign table命令创建数据存放在对象存储的外表,然后使用insert的方式将对象存储的数据迁移至同区域的 ProtonBase 中。
具体操作如下
-- 创建扩展插件
CREATE EXTENSION file_fdw;
-- 配置数据封装服务器
CREATE SERVER s3_server FOREIGN DATA WRAPPER file_fdw OPTIONS (REGION 'cn-northwest-1');
-- 创建外表的用户匹配
CREATE USER MAPPING FOR public SERVER s3_server
OPTIONS (
ACCESS_ID '*****',
ACCESS_KEY '****'
);
-- 创建外表,指定s3位置
CREATE FOREIGN TABLE public.category
(catid smallint, catgroup text, catname text , catdesc text)
SERVER s3_server
OPTIONS (dir 's3://s3bucket/robert/category/', format 'parquet')
CREATE FOREIGN TABLE public.date
(dateid int,caldate date,day text ,week int,month text,qtr text ,year int,holiday boolean)
SERVER s3_server
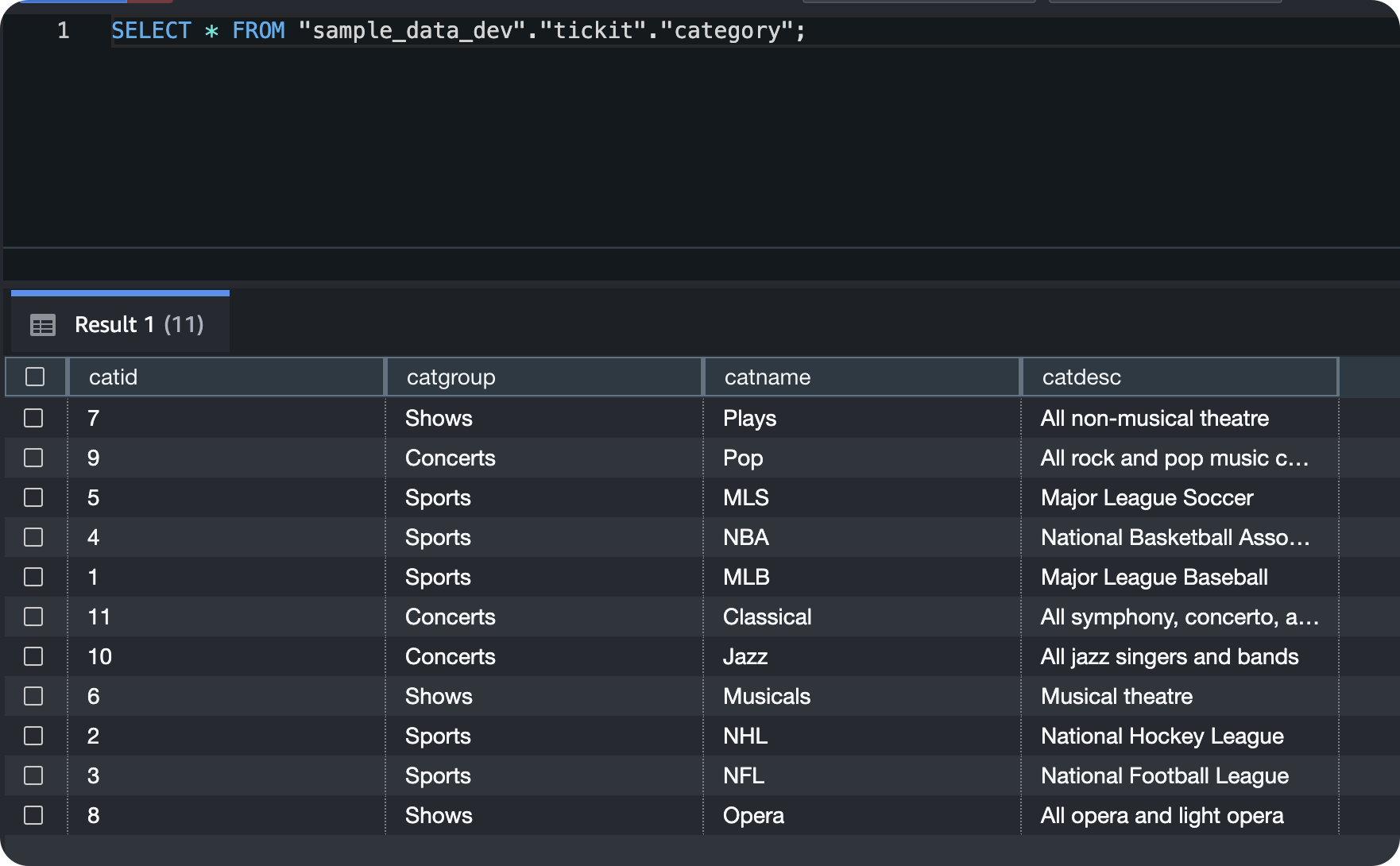
OPTIONS (dir 's3://s3bucket/robert/date/', format 'parquet')执行如下命令查看和校验数据导入结果。
SELECT * FROM public.category limit 100;返回结果示例如下。
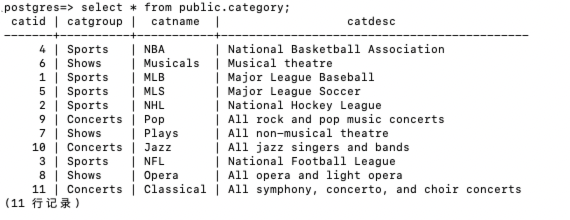
在redshift中进行查询。两边的数据是可以对应上。