所有数据 所有场景 挑战极限 极简体验
ProtonBase 是一个多云原生系统,能够存储所有的数据,在所有场景挑战性能、正确性和实时性的极限,并且给开发和运维带来极致体验。

更好的关系型数据库
ProtonBase 可以被视为关系型数据库使用,且 ProtonBase 是一个更好的关系型数据库。
使用 PostgreSQL 这种单机的关系型数据库存储所有数据遇到的问题是:当性能达到单机瓶颈时就没法满足业务对性能的需求了。而 ProtonBase 可以通过水平扩容的方式,通过增加更多的机器、更多的资源来满足业务不断增长的性能需求。而水平扩容的一个重要前提就是对分布式事务的支持,有了分布式事务的支持,系统就能够在水平扩容的同时保证数据的强一致。
除了这个能力,系统还引入了 JSON 类型以更好地处理半结构化数据。
同时随着近几年人工智能的飞速发展,文本、图像、音视频这些非结构化数据被赋予了一种新的结构,即嵌入向量。在引入了向量数据的支持之后,我们就能够把结构带给传统的非结构化数据,以方便从中提取出重要的知识。
更好的NoSQL数据库
用户也可以把 ProtonBase 当做一个 NoSQL 数据库来使用。跟传统的 NoSQL 数据库相比,ProtonBase 的优势之一是能表达所有关系。

NoSQL 数据库中最流行的一类是文档型数据库。文档型数据库采用文档模型代替关系模型,能够很好地描述实体之间一对一和一对多的关系。它的不足之处在于:对于多对多的实体关系没有好的处理方式。用户可以选择把一些实体存储在多个文档中,但这会导致数据的重复,进而导致修改时数据的不一致。用户也可以选择使用引用去表达这种关系,但是引用的一致性难以得到保证。
ProtonBase 引入了 JSON 这种类型,因此在面对一对一和一对多的关系时,ProtonBase 能够像 NoSQL 数据库一样用 JSON 表达半结构化数据。同时在处理多对多的关系时,ProtonBase 可以通过关系模型的外键来表达。因为 ProtonBase 支持分布式事务,所以能够真正保证这些外键永远一致。作为一个 NoSQL 数据库,ProtonBase 完全涵盖了 NoSQL 数据库的所有能力和优势,能够很好地表达半结构化数据,同时完美地表达多对多的关系,并保证这些多对多关系的强一致。
除此之外,ProtonBase 还支持 SQL 查询语言,这就意味着系统可以做 Join,聚合等更加复杂的查询分析。各种工具对 SQL 都有着非常好的支持,这就意味着 ProtonBase 的用户可以方便地使用各种生态工具,提升自己的开发效率。
更好的搜索引擎
ProtonBase 还可以被视为搜索引擎来使用,并提供一体化的统一搜索能力。作为一个搜索引擎,ProtonBase 同时具备关键词搜索和语义搜索的能力,也可以进行结构化数据的过滤。
如果用户把原始数据存储在 ProtonBase 中,不需要搜索引擎与业务数据库之间同步数据,因而也不会有同步带来的数据延迟问题。如果把 ProtonBase 当做一个搜索引擎,它能够保证搜索结果永远建立在最新的数据之上,彻底解决数据延迟的问题。同时还能够保证数据永远是强一致的,也就是说搜索返回的结果永远不会自相矛盾。
更好的数据仓库
ProtonBase 也是分布式数据仓库。ProtonBase 支持高吞吐低延迟的实时数据写入与更新,能够在保证高性能的同时保证数据的强一致和数据的无延迟,支持高并发交互式查询和毫秒级体验,支持开放的湖仓融合能力。

-
一种常见的做法是批量写入数据到数仓。例如,每五分钟积累一批数据,然后一次性将这些数据写入数仓。这种做法可以实现较好的性能和数据正确性,但在实时性方面表现不理想。数据延迟可以做到小时级或五分钟级,最多降至一分钟级,在合理利用资源的情况下很难实现更低的数据延迟。大部分数仓和数据湖都采用了这种方案,虽然它们满足了性能和正确性的需求,但是准实时不等于实时,无法做到真正的实时。
-
另一类数仓支持数据的实时写入,但是这类系统往往只保证最终一致性。最终一致性可以简单理解为如果系统一段时间没有写入数据后再去查询,此时看到的数据是一致的。最终一致性的问题在于有持续不断的实时写入时,“最终”可能永远不会发生,因此在查询时可能遇到数据不一致的情况。比如,当上游同步过来一笔转账交易,它包含两个更新:一个是从原账户的转出;另一个是在新账户的转入。虽然系统在同步的时候保证了这两个修改都被正确地同步到数仓中,但是在读取时可能只读到了当中的一个修改,如果系统计算总金额就会得到错误的结果。在这个例子中,上游的修改在一个事务里,同步后丢失了这个事务的属性导致了不一致。我们往往比较重视写入的原子性,而容易忽略读取的原子性,但读取的原子性对保证数据的正确至关重要。这种做法虽然满足了业务的性能和实时的需求,但是最终一致不等于一致,读取的数据可能会不一致,无法真正满足业务对数据正确性的要求。
极简体验
ProtonBase 在数据库场景是一个更好的数据库,在 NoSQL 场景是一个更好的 NoSQL 引擎,在搜索场景是一个更好的搜索引擎,在数仓场景是一个更好的数仓。
从开发和运维的视角来看,ProtonBase 提供了极简体验。
- 统一的API:ProtonBase 提供统一的 API ,降低用户使用门槛。
- 统一的数据存储:所有的数据都是一份存储,这意味着用户不再需要数据同步任务。
- 兼容开源生态:ProtonBase 兼容了 PostgreSQL 的生态,用户能够复用关系型数据库的知识,不需要去学习一门新的技能。
- 隔离:ProtonBase 具备较好的隔离能力,可以保证不同的工作负载之间互不影响。
- 自适应:ProtonBase 通过自适应的能力保证在所有的场景都达到最优。
数据同步
ProtonBase 内置数据同步服务,支持多种数据源数据实时同步到数据库中。
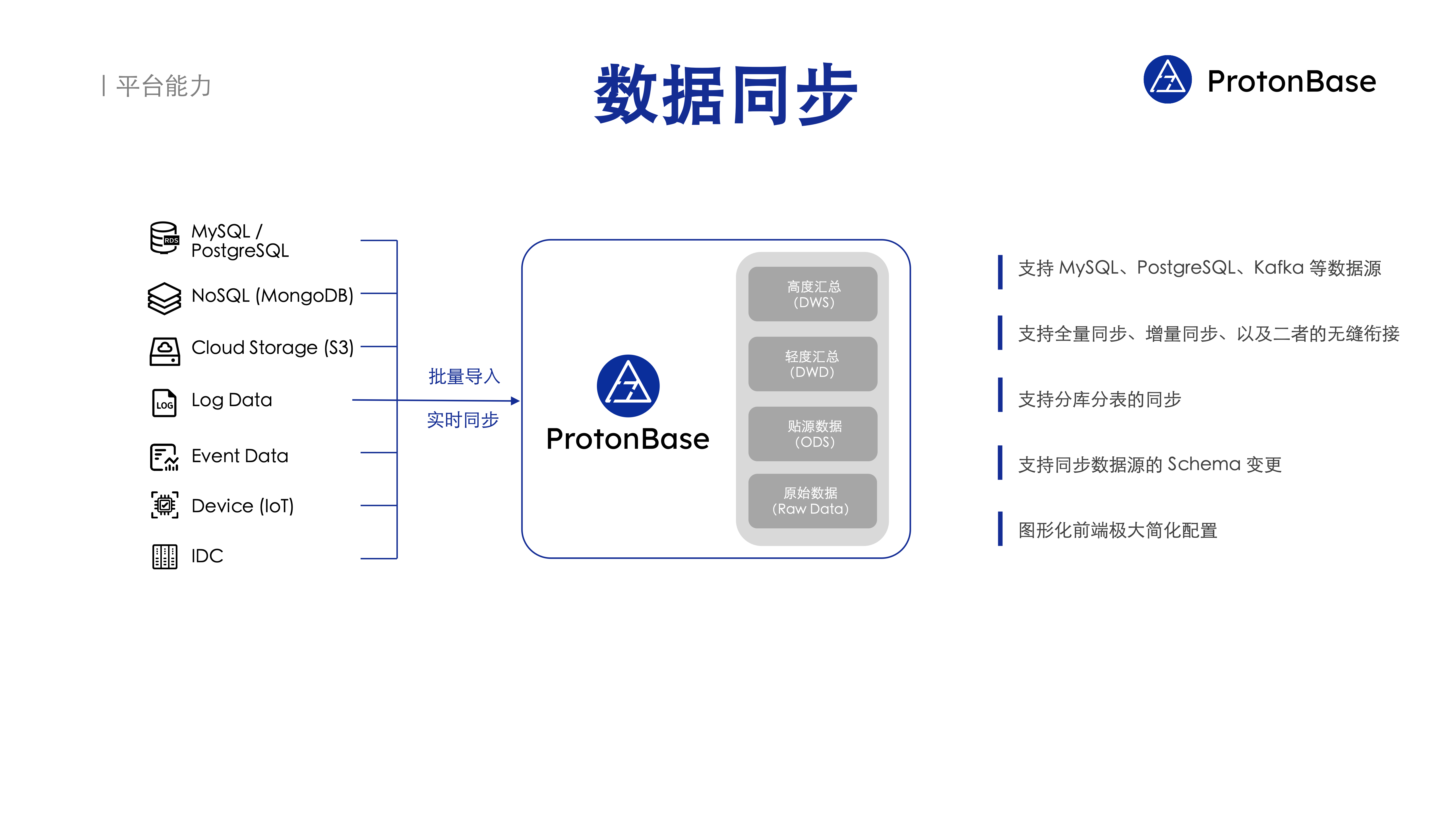
- 支持 MySQL、PostgreSQL、Kafka 等数据源
- 支持全量同步、增量同步、以及二者的无缝衔接
- 支持分库分表的同步:无需手动分库分表,数据同步服务支持把同步数据源的分库分表的数据同步到 ProtonBase 一张表中。
- 支持同步数据源的 Schema 变更:数据同步服务支持同步上游数据源表结构的变更,包括增加表,增加字段,更改字段类型等变更。