表设计
CREATE TABLE 语句用于在数据库中创建新表。以下是一些指引,以帮助您在 ProtonBase 中创建新表。
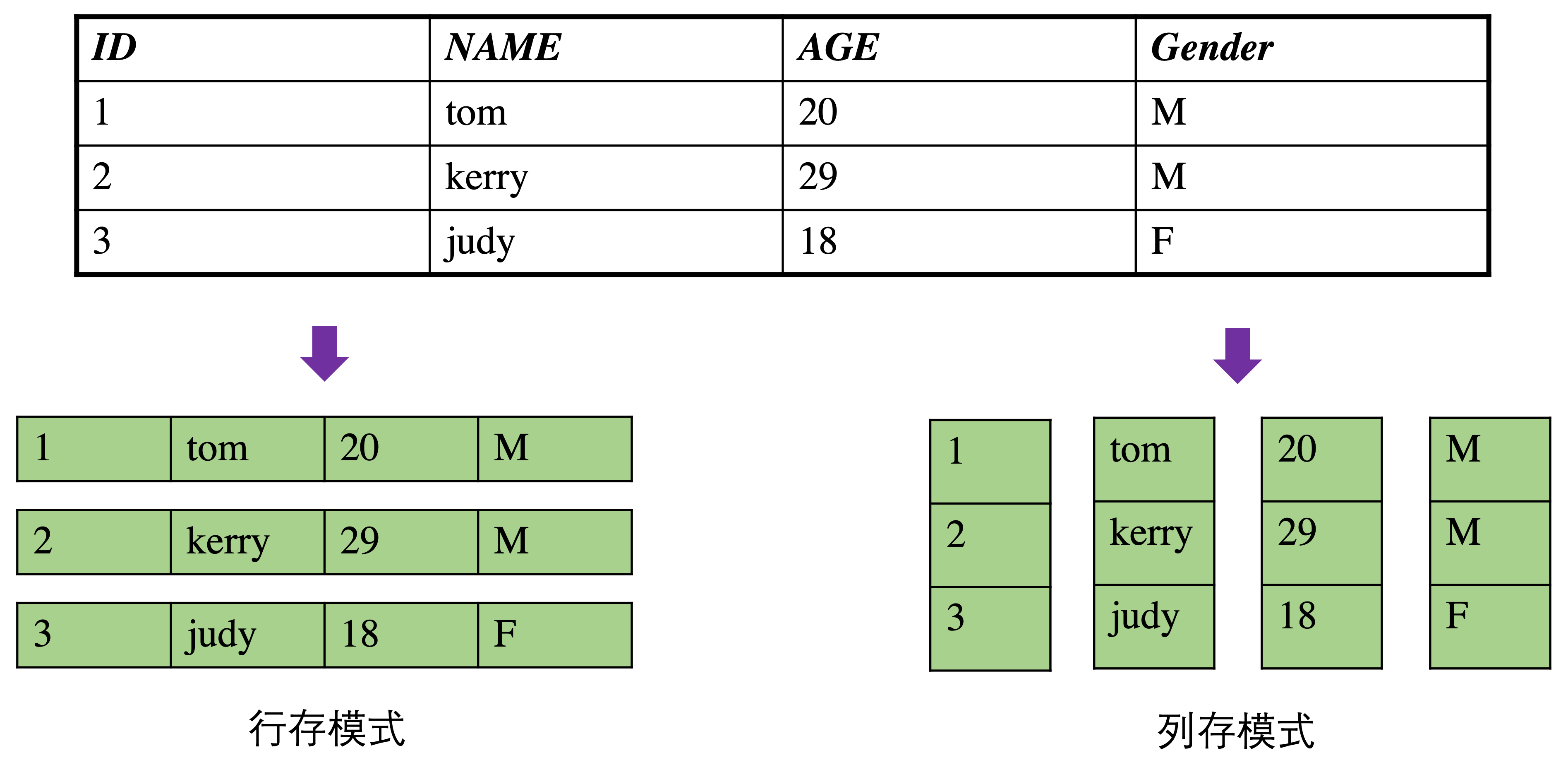
表的存储模式
ProtonBase 中的表包括三种存储模式:行存、列存和行列混存。每种存储方式都有其自己的优点和用途。
行存 (Row Store)
在行存模式下,单个行的数据存储在一起。这是传统关系数据库最常见的布局。
特点:
- 表的默认存储方式是行存
- 适合 OLTP(在线事务处理)型应用场景
- 需要频繁进行插入、更新和基于整行数据的查询
- 能够提供较高的写入性能和较低的查询延迟
适用场景:
- 数据插入和更新频繁的场景
- 需要基于单行数据进行查询的应用
- 传统的事务型应用,例如电商订单管理、银行系统等
-- 创建一张行存表 (默认存储模式)
CREATE TABLE row_t(
id int PRIMARY KEY,
name text,
age smallint,
gender char(1)
);
-- 显式指定行存模式
CREATE TABLE tbl(
id int PRIMARY KEY,
name text,
age smallint,
gender char(1)
) USING row;列存 (Columnar Store)
在列存模式下,每列的数据存储在一起。
特点:
- 对于分析工作负载非常高效
- 查询特定列而不是所有数据时,可以减少 I/O 并提高查询性能
- 非常适合 OLAP(在线分析处理)型应用场景
适用场景:
- 数据查询较为复杂,涉及大量数据的统计、分析和聚合操作
- 需要读取大量数据中的部分列进行计算,且列间的数据变化较小
- OLAP(在线分析处理)型应用,如数据仓库和日志分析
-- 创建一张列存表
CREATE TABLE columnar_t(
id int PRIMARY KEY,
name text,
age smallint,
gender char(1)
) USING columnar;行列混存 (Hybrid Store)
混合存储结合了行存和列存的优点。
特点:
- 表的某些列会以行存的方式存储,而其他列则以列存的方式存储
- 适用于需要既支持 OLTP 又支持 OLAP 的场景
- 使用混合存储消耗的存储空间会更多
适用场景:
- 需要同时支持事务处理和大规模数据分析的混合型应用
- 在同一表中既有频繁更新的数据,也有需要高效查询的分析型数据
-- 创建一张行列混存表
CREATE TABLE hybrid_t(
id int PRIMARY KEY,
name text,
age smallint,
gender char(1)
) USING hybrid;表存储模式的选择取决于您应用程序的特定要求和查询模式。
更多有关建表的语法说明,请参考 CREATE TABLE
主键设计
主键(Primary Key,PK)是表中每一行的唯一标识符。大多数情况下,为了确保数据的唯一性和完整性,会在表上定义主键。
设计原则
在设置主键时,请考虑以下事项:
-
唯一性:主键必须包含每一行的唯一值。ProtonBase 会自动强制执行此要求。
-
效率:选择一个经常用于查询和连接表的列或一组列。这有助于优化查询性能。
如果主键中包含多列,主键中列的顺序会显著影响底层索引查找的效率。只有在先导列(最左侧)上存在约束时才会高效。
具体规则是,在先导列上的等值约束,加上第一个不等值约束的列上的不等值约束,将被用于限制索引被扫描的部分。
例如,假设主键是(a,b,c),查询条件为
WHERE a = 5 AND b >= 42 AND c < 77,那么索引将从具有 a = 5 和 b = 42 的第一个条目扫描,一直到具有 a = 5 的最后一个条目。 -
稳定性:尽量避免那些可能经常更改的列作为主键,因为这可能导致更新变慢。
要设置主键,请在表定义中使用 PRIMARY KEY 约束:
CREATE TABLE users (
user_id text PRIMARY KEY, -- PRIMARY KEY 表示这是主键
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 组合主键
CREATE TABLE order_items (
order_id INT NOT NULL,
product_id INT NOT NULL,
quantity INT NOT NULL,
price DECIMAL(10, 2) NOT NULL,
PRIMARY KEY (order_id, product_id) -- 组合主键由 order_id 和 product_id 共同组成
);避免的误区
在定义主键时,应避免以下一些不好的示例:
- 不要总是将自增 id 字段作为主键,特别是当 id 字段实际上并未在用户的所有查询中使用时。自增 id 字段会影响写入性能。
- 不要在单一单调列上定义主键,例如在自增列或按时间戳递增的列上,这会影响写入性能。
电商系统示例
以下是一个电商系统的表设计示例,展示了如何在实际业务场景中应用主键设计原则:
-- 用户表:使用业务字段作为主键
CREATE TABLE users (
user_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
username VARCHAR(50) NOT NULL UNIQUE,
email VARCHAR(100) NOT NULL UNIQUE,
phone VARCHAR(20),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 商品类别表:使用业务字段作为主键
CREATE TABLE categories (
category_id SERIAL PRIMARY KEY,
category_name VARCHAR(100) NOT NULL UNIQUE,
description TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 商品表:使用业务字段作为主键
CREATE TABLE products (
product_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
product_name VARCHAR(200) NOT NULL,
category_id INT REFERENCES categories(category_id),
price DECIMAL(10, 2) NOT NULL,
stock_quantity INT NOT NULL DEFAULT 0,
description TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 订单表:使用业务字段作为主键
CREATE TABLE orders (
order_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id UUID NOT NULL REFERENCES users(user_id),
order_status VARCHAR(20) NOT NULL DEFAULT 'pending',
total_amount DECIMAL(10, 2) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 订单项表:使用组合主键
CREATE TABLE order_items (
order_id UUID NOT NULL REFERENCES orders(order_id),
product_id UUID NOT NULL REFERENCES products(product_id),
quantity INT NOT NULL,
unit_price DECIMAL(10, 2) NOT NULL,
PRIMARY KEY (order_id, product_id)
);不同存储模式的应用场景
以下示例展示了如何根据不同业务场景选择合适的存储模式:
-- 1. OLTP场景:用户交易表(行存)
CREATE TABLE user_transactions (
transaction_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id UUID NOT NULL,
amount DECIMAL(10, 2) NOT NULL,
transaction_type VARCHAR(20) NOT NULL,
status VARCHAR(20) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) USING row;
-- 2. OLAP场景:销售数据仓库表(列存)
CREATE TABLE sales_analytics (
sale_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
product_id UUID NOT NULL,
user_id UUID NOT NULL,
quantity INT NOT NULL,
unit_price DECIMAL(10, 2) NOT NULL,
total_amount DECIMAL(10, 2) NOT NULL,
sale_date DATE NOT NULL,
region VARCHAR(50),
category VARCHAR(50)
) USING columnar;
-- 3. HTAP场景:用户行为分析表(行列混存)
CREATE TABLE user_behavior (
user_id UUID NOT NULL,
session_id UUID NOT NULL,
event_type VARCHAR(50) NOT NULL,
event_data JSONB,
event_timestamp TIMESTAMP NOT NULL,
device_type VARCHAR(20),
browser VARCHAR(50),
PRIMARY KEY (user_id, session_id, event_timestamp)
) USING hybrid;存储模式管理
修改表存储模式
可以通过 ALTER TABLE SET ACCESS METHOD 动态修改表的存储格式:
-- 改为行存
ALTER TABLE xx SET ACCESS METHOD row;
-- 改为列存
ALTER TABLE xx SET ACCESS METHOD columnar;
-- 改为行列混存
ALTER TABLE xx SET ACCESS METHOD hybrid;修改过程会消耗一定的计算和存储资源,支持在线修改,在修改期间不会锁表,对于表的读写操作不会受影响。
查看表存储模式
可以通过查看系统表的方式来获取当前表的存储格式:
SELECT amname
FROM pg_catalog.pg_class c
LEFT JOIN pg_catalog.pg_class tc ON (c.reltoastrelid = tc.oid)
LEFT JOIN pg_catalog.pg_am am ON (c.relam = am.oid)
WHERE c.oid = (select 'public.trade'::regclass::oid);
amname
--------
hybrid
(1 row)表结构复制
CREATE TABLE LIKE
基于现有表的表结构创建一个空表。创建一个空表,复制目标表的结构以及约束,如 NOT NULL。
CREATE TABLE LIKE 语法通常用于数据库管理和维护任务,例如在一个数据库中创建与另一个表相同结构的临时表,或者将表的结构复制到另一个 schema 下。
-- 复制表结构(包括所有约束)
CREATE TABLE t2(LIKE t INCLUDING ALL);创建的时候,您可以同时指定表的存储模式:
CREATE TABLE t2(LIKE t INCLUDING ALL) USING columnar;
CREATE TABLE t2(LIKE t INCLUDING ALL) USING hybrid;使用示例
-- 创建原始表
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
department VARCHAR(50),
salary DECIMAL(10, 2),
hire_date DATE NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建结构相同的表(包括所有约束)
CREATE TABLE employees_backup (LIKE employees INCLUDING ALL);
-- 创建结构相同但使用列存的表
CREATE TABLE employees_analytics (LIKE employees INCLUDING ALL) USING columnar;
-- 创建结构相同但不包括约束的表
CREATE TABLE employees_temp (LIKE employees INCLUDING DEFAULTS);CREATE TABLE AS SELECT (CTAS)
从 SELECT 语句创建表。使用 CREATE TABLE AS SELECT 语句,您可以复制整个表、特定记录或仅表的结构。
请注意,这个命令无法复制索引或约束,如
NOT NULL、主键、外键等。
CREATE TABLE t2 AS SELECT * FROM t WHERE age > 18;使用示例
-- 创建包含所有数据的表副本
CREATE TABLE employees_copy AS SELECT * FROM employees;
-- 创建包含特定数据的表
CREATE TABLE high_salary_employees AS
SELECT * FROM employees WHERE salary > 100000;
-- 创建仅包含表结构的空表
CREATE TABLE employees_structure AS SELECT * FROM employees WHERE 1=0;
-- 创建聚合数据表
CREATE TABLE department_salary_stats AS
SELECT
department,
COUNT(*) as employee_count,
AVG(salary) as avg_salary,
MAX(salary) as max_salary,
MIN(salary) as min_salary
FROM employees
GROUP BY department;特殊表类型
自增表
要创建一个具有自动递增主键的表,您可以使用 SERIAL 数据类型作为主键列的数据类型。
注:
SERIAL确保了单调递增,但是会影响写入性能。尽量选用业务字段作为主键。
CREATE TABLE t(id serial PRIMARY KEY, b int);
CREATE TABLE
INSERT INTO t(b) VALUES (1), (2), (4);
INSERT 0 3
SELECT * FROM t;
id | b
----+---
1 | 1
2 | 2
3 | 4
(3 rows)外键表
要创建一个具有外键约束的表,您可以使用以下示例。假设您有两个表,一个名为 "weather",另一个名为 "cities",并且您想确保在 "weather" 表中插入的行必须有一个在 "cities" 表中匹配的条目。
CREATE TABLE cities (
name varchar(80) PRIMARY KEY,
location point
);
CREATE TABLE weather (
city varchar(80) REFERENCES cities(name),
temp_lo int,
temp_hi int,
prcp real,
date date
);外键约束应用示例
-- 创建国家表
CREATE TABLE countries (
country_code CHAR(2) PRIMARY KEY,
country_name VARCHAR(100) NOT NULL
);
-- 创建城市表,外键引用国家表
CREATE TABLE cities (
city_id SERIAL PRIMARY KEY,
city_name VARCHAR(100) NOT NULL,
country_code CHAR(2) NOT NULL REFERENCES countries(country_code),
population BIGINT
);
-- 创建用户地址表,外键引用城市表
CREATE TABLE user_addresses (
address_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id UUID NOT NULL,
street_address VARCHAR(200) NOT NULL,
city_id INT NOT NULL REFERENCES cities(city_id),
postal_code VARCHAR(20),
is_default BOOLEAN DEFAULT false
);
-- 插入示例数据
INSERT INTO countries (country_code, country_name) VALUES
('US', 'United States'),
('CA', 'Canada'),
('UK', 'United Kingdom');
INSERT INTO cities (city_name, country_code, population) VALUES
('New York', 'US', 8336817),
('Los Angeles', 'US', 3979576),
('Toronto', 'CA', 2930000);
-- 查询关联数据
SELECT
ua.street_address,
c.city_name,
co.country_name,
ua.postal_code
FROM user_addresses ua
JOIN cities c ON ua.city_id = c.city_id
JOIN countries co ON c.country_code = co.country_code;分区表
分区通常用于提高查询性能和更有效地管理大量数据。分区表的介绍及例子详见这里。
修改表结构
支持在线修改表结构,简化运维工作,具体参考文档表结构修改。
最佳实践
表设计原则
-
选择合适的存储模式:
- OLTP场景使用行存
- OLAP场景使用列存
- 混合场景使用行列混存
-
合理设计主键:
- 优先使用业务字段作为主键
- 避免使用单调递增字段作为主键
- 组合主键要考虑查询模式
-
数据类型选择:
- 根据业务需求选择最合适的数据类型
- 避免过度使用大字段类型
- 合理使用JSONB存储半结构化数据
性能优化建议
-
索引设计:
- 为经常查询的字段创建索引
- 避免创建过多索引影响写入性能
- 考虑使用复合索引优化多条件查询
-
分区策略:
- 对于大表考虑按时间或业务维度分区
- 合理设置分区数量,避免过多小分区
- 定期维护分区表,清理过期数据
-
存储优化:
- 根据查询模式选择合适的存储模式
- 定期分析表的访问模式,调整存储策略
- 使用分层存储管理冷热数据
数据完整性保障
-
约束使用:
- 使用NOT NULL约束确保数据完整性
- 合理使用外键约束维护数据一致性
- 使用CHECK约束限制数据范围
-
默认值设置:
- 为常用字段设置合理的默认值
- 使用时间戳字段记录数据创建和更新时间
- 避免过度使用默认值影响业务逻辑
通过遵循这些最佳实践,您可以设计出高性能、易维护的表结构,充分发挥ProtonBase的分布式数据库优势。