极简体验
兼容 PostgreSQL 生态
可以将 ProtonBase 视为一个具备更丰富的功能,且能无限水平扩展的 PostgreSQL。ProtonBase 不但能适用传统的数据库场景,还拥有高效搜索以及高性能分析的能力,满足业务各种复杂的数据需求。

-
驱动:ProtonBase 兼容 PostgreSQL 的生态,这意味着 ProtonBase 能够无缝沿用 PostgreSQL 的驱动,如 JDBC/ODBC Driver。
-
开发框架:ProtonBase 还能直接使用为 PostgreSQL 开发的各种框架,比如 Hibernate,Mybatis,SQLAIchemy,Gorm 等等这些 ORM 框架。
-
开发工具:ProtonBase 可以使用支持 PostgreSQL 的主流开发工具,比如 psql,pgAdmin,DBeaver,DataGrip 等等。
-
BI工具: ProtonBase 可以使用各种主流 BI 工具,选择 PostgreSQL 类型即可连接,比如 Tableau,Metabase,Superset,帆软,Quick BI等等。
-
ETL工具:ProtonBase 支持使用各种 ETL 工具,比如 DBT 。
-
文档:ProtonBase 可以在大部分情况下复用 PostgreSQL 的文档。当用户不知道该如何编写或者调优一个 SQL ,或者不知道该如何设计表结构的时候,可以寻找搜索引擎的帮助,找到的答案在绝大部分情况下适用于 ProtonBase。
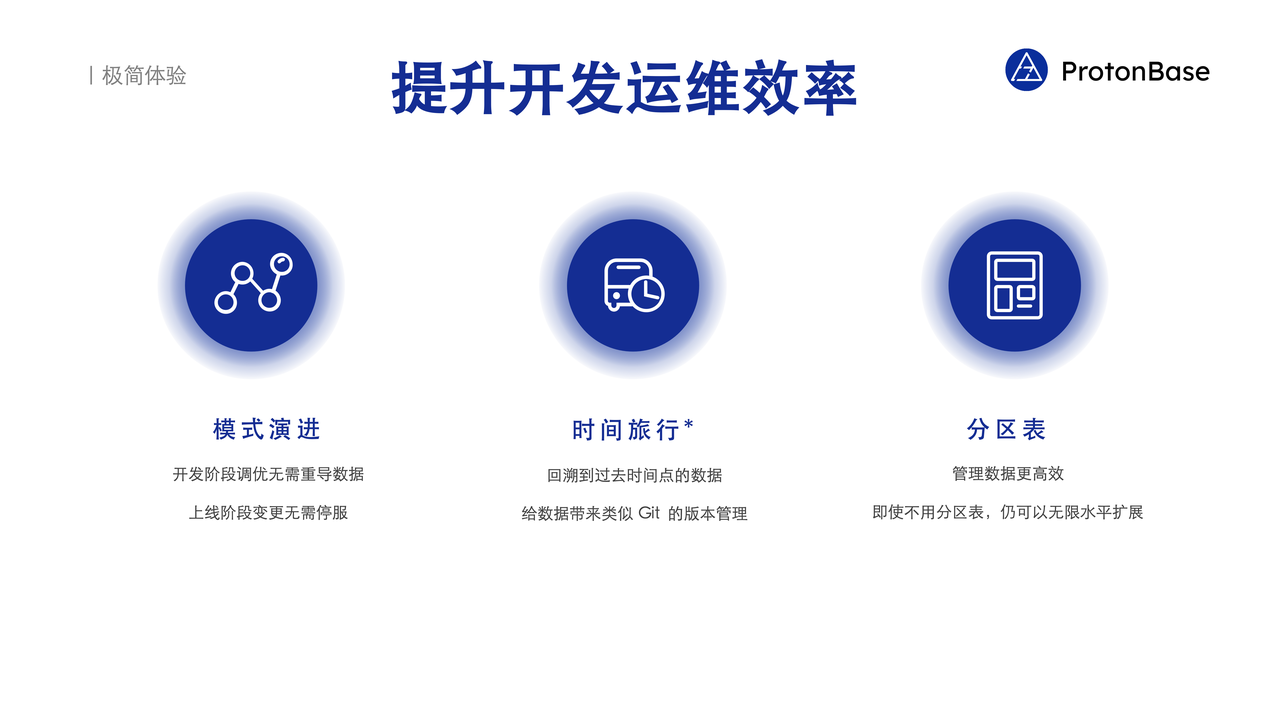
提升开发运维效率
为了进一步提升开发和运维的效率,ProtonBase 设计了多种高级功能。
-
Schema Evolution(模式演进):在业务使用过程尤其是开发过程中,表的结构很难一开始就完全确定。业务持续会有新的需求,包括为表添加 / 删除 / 修改字段的类型、增加约束、增加索引、甚至修改表的存储类型等等。为了简化这些操作,ProtonBase 引入完整的 **Schema Evolution (模式演进)**能力。允许用户通过 ALTER TABLE 这种方式一个语句即可轻松完成表结构的修改,而不需要重新导入数据。在上线阶段,因为新的业务需求而去修改表结构也很常见,模式演进功能大部分情况下均可在线完成。这意味着即使用户的应用程序已经上线并正在运行,仍然可以在不影响线上流量的前提下直接在线上进行表结构的修改,实现业务新的功能或需求更新。这对业务开发和上线的效率同样带来了巨大的提升。
-
Time Travel(时间旅行):比如在机器学习的场景,经常需要对数据做各种各样的实验。这些实验会对数据进行修改、清洗和变换。ProtonBase 提供了时间旅行的能力,用户可以回到过去某一点的数据,同时用户可以像使用 Git 一样管理数据库。例如,如果用户想要对数据做些实验,可以像在 Git 中创建分支一样为数据库创建一个分支,然后在该分支上进行实验。如果不想保留实验结果,可以轻松切回原来的分支。这种功能对于从事数据科学的工程师来说尤为方便。
时间旅行这个功能允许用户回溯到过去某一时间点的数据库状态。数据物理上分布于多台机器,这些机器必须看到过去同一时刻的数据,而这些机器之间存在时间差异,要实现完全对齐并且维持它们的时钟在物理上是不可能的。而这正好给了我们一个更深刻地理解时间的机会。当我们说某个时刻,我们所想到的是那个时刻所能看到的一切。想象一下很多小鸟在飞,你在某个时刻按下快门拍了一张照片,这张照片就定义了那个时刻。但是这张照片所看到的并非真的是同一时刻发生的事件。小鸟的嘴巴和翅膀离相机的距离不一样,所以光到达相机所需的时间也不一样,所以照片记录的其实是不同时刻发生的事件。但是为什么我们从来没有为此困扰呢?除了光很快、时间的差距很小外,更重要的原因是这张照片里的内容是一致的,即不违背因果关系的。比如说你永远不会见到鸟的嘴尖出现在照片的两个地方,这个是距离不等式和任何物体不能超过光速旅行的推论。所以真正重要的是一致性,而时间可以理解为一致性的快照。按照这种思路,我们高性能地在分布式场景实现了数据库的快照。
- 分区表:它能够帮助用户更高效地管理数据。ProtonBase已经提供了冷热数据分层的能力,一个比较好的使用方式是,用户把每天的数据放在一个分区里,在热存储中保留一个星期或者一个月的数据,更老的分区则放到冷存储中。值得一提的是,ProtonBase 是一个分布式的 Data Warebase ,本身就具有分布式的能力,因此扩展性不依赖于分区表,即使不使用分区表,用户的任何表都是可以无限水平扩展的。分区表不是性能层面的功能,而是管理层面的功能,用户可以借助它更高效地管理数据。
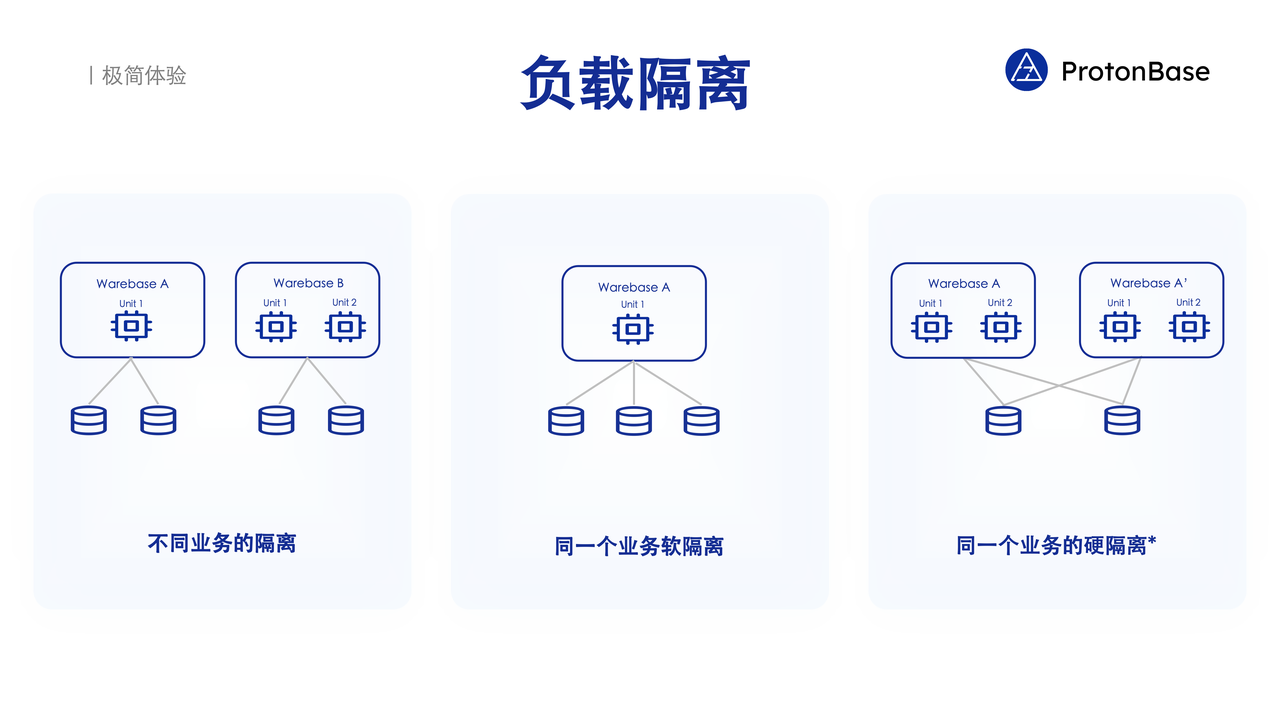
负载隔离
在 ProtonBase 上可能同时运行着多种工作负载,如何在不同工作负载之间做好隔离至关重要。 ProtonBase 提供三种工作负载的隔离方式。
-
不同业务间的隔离:一个公司内部可能会有不同的业务,它们使用完全不同的数据,也希望使用不同的计算资源。这个时候,每个业务都可以创建自己的数据库,创建自己的 Warebase ,从而在资源层面完全隔离开,这是不同业务之间最简单的隔离方式。
-
同一个业务内的软隔离:同一个业务也可能有不同的工作负载、不同的流量,比如,有的流量是在线的请求,有的则不是。一个电商用户搜索有哪些商品满足自己的需求,并且购买支付,这些都是在线的需求。同时,后台会有运营进行复杂的分析。为了让后台的分析请求不影响到前台的业务,ProtonBase 可以在一个 Warebase 内部用软件的方式对不同的流量进行隔离,保证复杂的后台查询不会挤压前台业务所需要的计算资源。
-
同一个业务内的硬隔离:也就是通过只读实例的方式实现同一份数据上不同负载之间的硬隔离。比如,ProtonBase 可以用 Warebase A 服务前台的流量,而 Warebase A' 作为 Warebase A 的只读实例,可以给后台运营做各种复杂的分析。通过这种方式,ProtonBase 能够保证运营的任何操作都不会影响前台的用户的体验。
自适应
自适应是 ProtonBase 产品设计的核心能力,在 ProtonBase 中随处可见,我们始终致力于让系统自动做出最佳选择,为用户提供极简的体验。
-
数据自动分片与均衡:当用户创建一个数据库并写入数据时,如果数据量足够小,ProtonBase 会使用同一个计算单元来管理这个数据库的所有数据,因为这样最高效,额外开销最小。当数据量增大时,ProtonBase 会自动把这个数据库里的数据分片打散到多个计算单元中进行管理,因为这样能够提供更高的性能。而随着业务不断地增删改,数据的分布也会发生变化。在变化足够大时,ProtonBase 会自动迁移这些数据,保证各个计算单元之间达到平衡。
-
一阶段事务:虽然 ProtonBase 通过高性能的分布式的事务保证了系统的强一致,但分布式事务相对于简单的事务仍会有一定的额外开销。同时因为 ProtonBase 支持半结构化的数据,所以在很多场景中,用户需要修改的所有数据可能恰好分布在同一台机器之上。这个时候,ProtonBase 就会使用一阶段提交的方式实现事务,以避免分布式事务带来的额外开销。
-
查询自适应并行度:对简单的查询来说,最高效的方式是用单节点单并发执行,这样系统的额外开销最小。但是对复杂的分析查询,需要使用分布式执行计划,并且用更高的并发度,这样才能在比较短的时间内得到结果,从而给用户提供比较好的体验。ProtonBase 的查询引擎会进行自适应,决定什么时候采用单机单并发执行,什么时候采用分布式和多并发的执行方式。
ProtonBase 每设计一个功能 / 增加一个新的参数都极为克制谨慎。ProtonBase 是为最苛刻的业务场景,也就是最高的性能要求、最高的一致性要求和最高的实时性要求设计一个极致的系统。用户可能会问,如果我的实际业务要求并不那么苛刻,例如我可以牺牲一定的实时性,那么选择这样一个为最严苛需求而设计的系统是否会造成资源浪费?在我的实际业务场景中,这样的系统是否仍是最佳选择?自适应在这里至关重要。如果业务需求并不那么严格,系统完全可以根据业务特点做相应的优化,避免不必要的成本。如果实时性并不是某个分析业务最重要的考量因素,业务可以采用批量的方式写入数据,系统对批量数据的导入会做相应的优化,从而避免为极低延迟设计带来的额外性能开销,真正实现针对具体业务场景的最优。