挑战性能极限
在系统存储了所有数据之后,下一步就是如何高效地使用这些数据。不同场景使用数据的方式也会不一样,ProtonBase 希望在所有场景都能从性能、一致性和实时性上挑战物理极限。
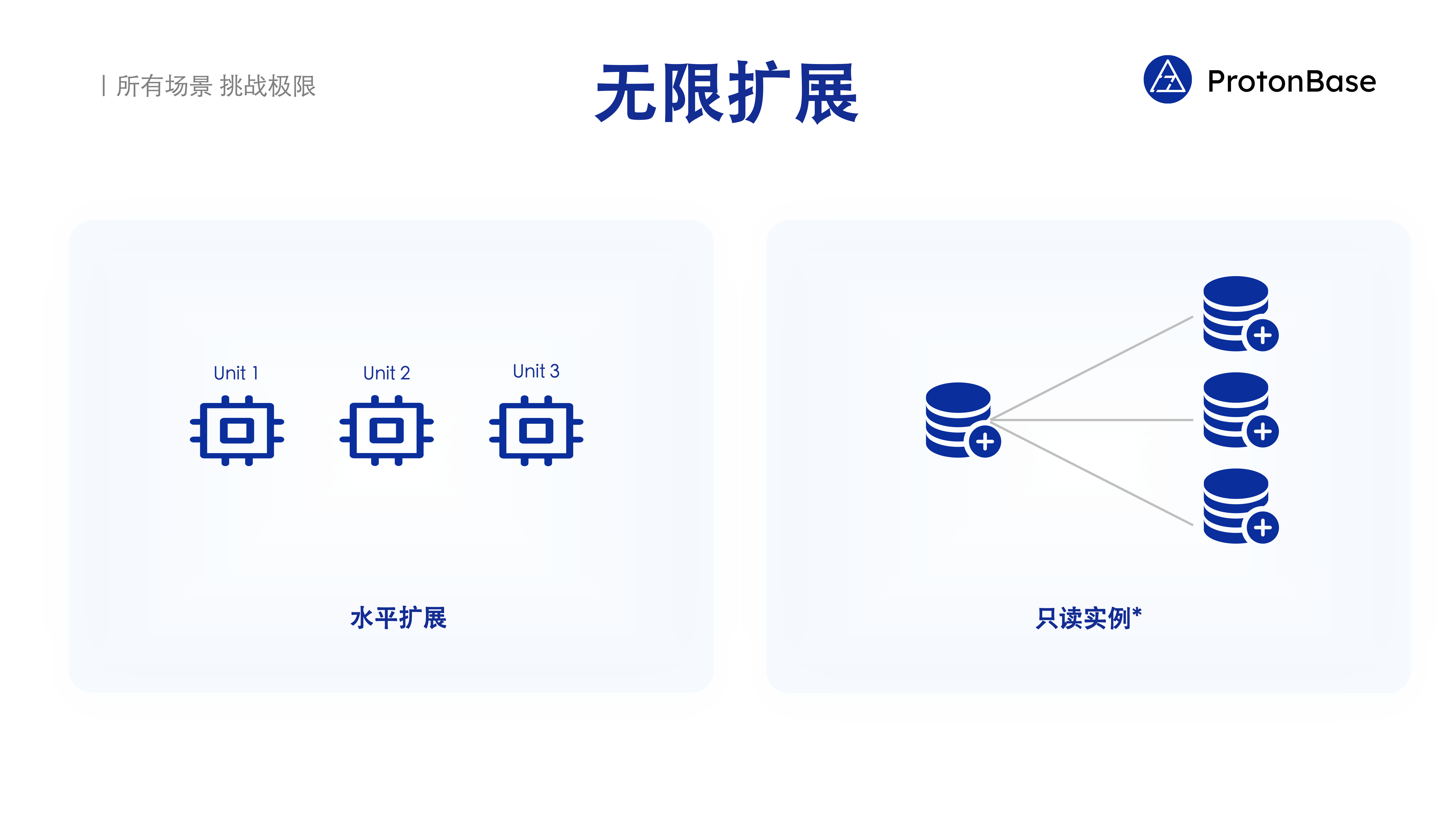
无限扩展
为了满足业务任意高的性能需求,ProtonBase 提供了无限扩展的能力。通过以下两种扩展方式,只要投入足够的计算资源,就能支持任意高的性能。
水平扩展:在一个 Warebase 里,通过增加 Unit 的方式去水平扩展计算资源,提升它的读写能力。
只读实例:在一些场景中,写请求和读请求完全不成比例,可能写请求不是特别高,但是读请求非常高,这时只读实例是提高读请求吞吐的更好方式。一个读写实例可以支持多个只读实例,这些只读实例方便我们去扩展读的能力。
高性能多场景查询
除了通过用更多的资源去支持更高的性能之外,ProtonBase 还希望在资源一定的情况下提供更高的性能。为了做到这一点,ProtonBase 使用了业界领先的向量化执行引擎,使用了多种索引为查询加速,比如说通过倒排索引加速关键词搜索,通过向量索引加速向量查询。在分析场景通过物化视图把一些经常查询的结果预计算并且存储下来,避免了不必要的重复计算。

通过这一系列的工作,ProtonBase 就能够在简单查询、关键词搜索、向量搜索和复杂的分析查询场景都提供极高的性能和性价比。
高性能数据操作
ProtonBase 通过无限扩展和单机的高性能彻底解决了查询的性能问题,剩下的两个问题分别是数据的实时性和正确性的问题。在实时性方面,最重要的一点是数据实时增删改的能力,这里把它叫做交互式增删改。ProtonBase 能够高吞吐、零延迟地去处理实时的增删改需求。零延迟的意思是用户的修改一旦完成,立刻就能被查到,没有任何延迟。这种能力使得用户可以在线交互的方式去修改和查看数据。
在市场上,有些产品也支持“准实时”增删改的能力。在交互式的场景中,“准实时”带来的几秒的延迟也会极大地影响体验。因为延迟不可预测的波动,很难保证延迟在某个确定的范围内,因此会导致很多场景没法使用准实时的系统。ProtonBase 提供的交互式增删改的能力,使得它适用于更多场景。

除了增删改的实时性外,ProtonBase 还支持比较丰富的增删改的功能,比如 UPSERT/MERGE/UPDATE JOIN,同时我们还支持输出更新的数据的能力。这些能力使得修改业务的数据变得更加简单方便。
除此之外,ProtonBase还提供了高性能的数据导入导出的能力:
- 快速批量导入:海量数据的导入,可以用 COPY FROM ;
- 快速批量导出:大量数据的快速导出,可以用 COPY TO ;
- 实时流式同步:支持增量数据导出,和 PostgreSQL 的 CDC 完全兼容。通过这种能力,下游的任务可以监听到数据库中数据的修改,因此 Kafka / Flink 这些下游任务得以高效地驱动实时处理。用户还可以通过这个能力将一个数据库的数据逻辑同步到另外一个数据库中,甚至同步到其他数据产品中。
分布式系统具有多个计算节点,增量数据导出需要将多个节点管理的数据进行汇合,同时必须确保修改的顺序不被打乱,这使得实现高效的增量导出非常有挑战性。同时,为了去除下游业务的额外学习和开发成本,ProtonBase 完全兼容了 PostgreSQL 逻辑复制的协议。在不改变协议的前提下,高性能地实现分布式增量逻辑复制成为一个更大的挑战。用户不需要理解内在的复杂度,只需像使用单机版 PostgreSQL 的逻辑复制一样轻松使用 ProtonBase 的增量导出功能即可。
高性能分布式事务
ProtonBase 通过支持高性能的分布式事务,解决了数据修改过程中如何保证数据的强一致性。
![]()
完整的 ACID 语义:ProtonBase 的增删改严格遵循可序列化的事务语义。也就是说所有的数据修改在逻辑上都可以想象成按照顺序一个一个发生的,虽然实际上是高性能同步执行的。提供严格的事务语意保证了数据的完整性和一致性,大大降低了开发高性能业务的门槛。
多语句事务:用户可以在一个事务当中编写多个 SQL 语句,甚至大部分 DDL 也可以出现在多语句的事务中。相较于单个语句事务,这类事务具备更高的灵活性,能够适用更多的业务场景。
对话式事务:用户可以在事务中先向系统发起一个查询,根据查询的结果再决定接下来是进行另外一个查询还是进行增删改操作。对话式事务的支持为业务进一步扫清了障碍,简化业务的开发。
所有这些功能的前提是分布式,而且都必须同时保证性能和实时性。ProtonBase 通过高吞吐和低延迟的分布式事务,在各种业务场景挑战性能、实时性和一致性的物理极限,满足最苛刻的业务需求。