数据存储引擎
通过以下存储技术的创新,ProtonBase 能够高效低成本地存储所有的数据以及为它们创建各种索引。
多种存储格式
结构化数据可以用行或者列的格式存储,行存和列存各有利弊。大部分数据库系统多使用行存储的格式,这种格式把一行的所有数据连续地存在一起。行存储方式比较适合事务型的场景,能够高效地实时写入,支持高性能点查。大部分数仓系统多采用列存储的格式,这种格式把同一列的所有数据连续地存在一起。列存适合分析型场景,支持高效的多维过滤与聚合,有更高的压缩率,从而减少查询的 IO ,提升复杂查询的性能。
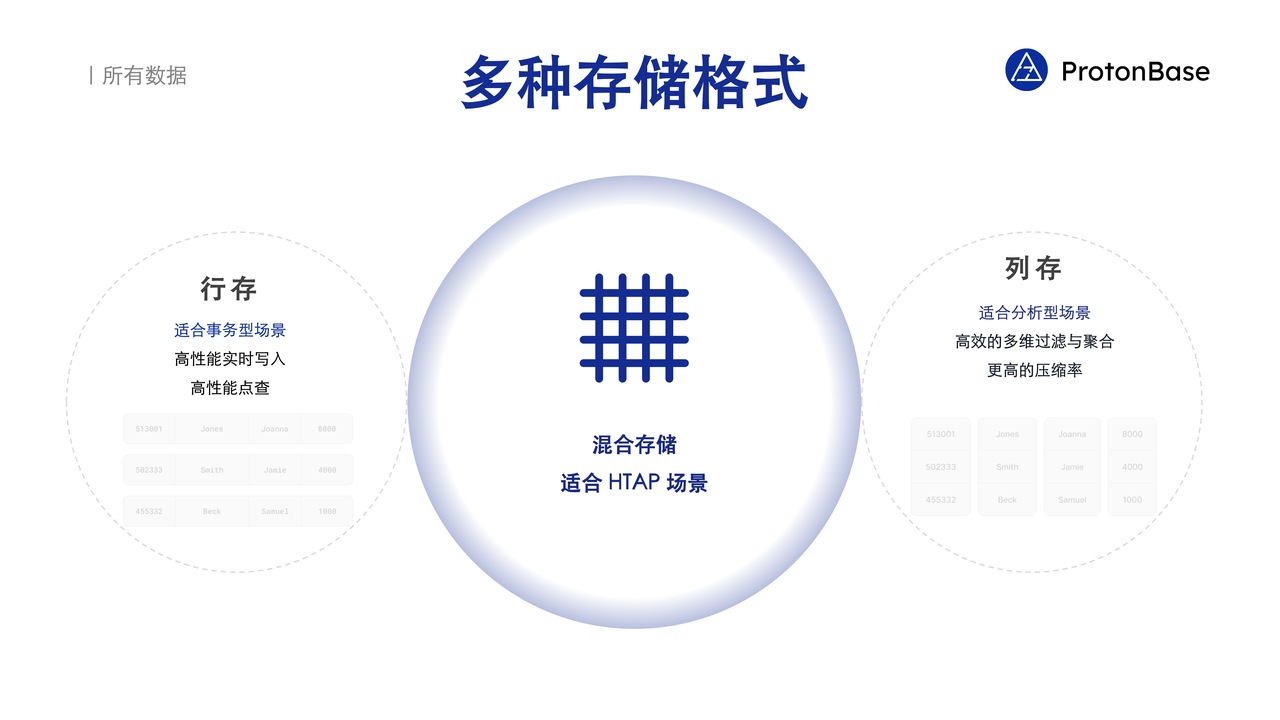
ProtonBase 既支持行存,也支持列存。在某些场景中,用户既有事务型需求,也有分析型需求,这个时候用户可以使用混合存储。混合存储兼具两种存储方式的优势,特别适合 HTAP(Hybrid Transactional/Analytical Processing) 场景,优化器会根据查询决定最高效的访问方式。
多种数据
除了结构化数据, ProtonBase 还通过 JSON 和 JSONB(Binary JSON,压缩的、列存化的、有索引的) 类型支持半结构化数据。 JSON 是一种层次化数据描述的方式,将数据组织成树形结构的文档形式。JSON 能够很灵活地表达这种半结构化数据。用户还可以把结构化数据和半结构化数据存储在同一张表中,并在此基础上高效地做结构化数据和半结构化数据的联合过滤。 ProtonBase 通过 JSON PATH 提供了丰富的查询能力,几乎可以满足业务对半结构化数据的所有查询需求。用户还可以同时使用 SQL 和 JSON PATH 对结构化数据和半结构化数据做复杂的联合查询。

为了更好地支持非结构化数据, ProtonBase 加入了高维向量的支持,引入Vector数据类型,用户可以把图像、文字和音视频的嵌入向量存储在数据库中,还可以把结构化数据、半结构化数据和向量数据存储在同一个表中,然后通过 SQL 去做各种复杂的查询。
ProtonBase 能够很好地同时存储和处理结构化数据、半结构化数据和非结构化数据,并且以嵌入向量的方式赋予非结构化数据新的结构。
丰富的索引
为了让查询更加高效就,ProtonBase 引入了丰富的索引来加速。
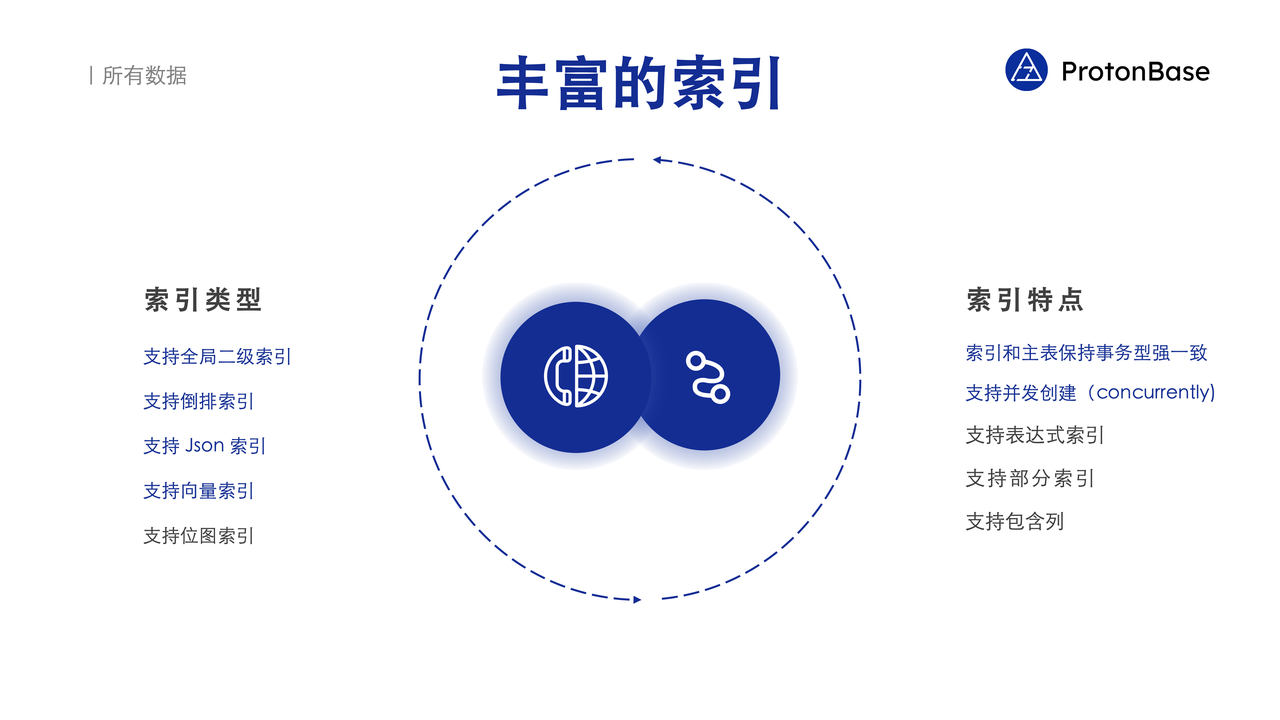
全局二级索引:如果用户需要通过某一个属性去查找一条记录,通过全局二级索引就能快速定位是哪一台机器存储了这条记录,并且高效地将它返回。全局二级索引使得系统在面临高吞吐的需求时,可以通过增加机器来达成目标。如果不支持全局二级索引,而只支持本地二级索引,系统接收的每一个查询都需要发送到每一台机器上,所以这类系统增加机器的时候,并不能提高这一类查询的吞吐,性能仍然会成为瓶颈。
倒排索引:方便支持关键词搜索的需求。系统支持了 JSON 索引,让 JSON PATH 这种 Query 也变得非常高效。支持向量索引,让相似性的搜索变得高效。支持位图索引,可以高效过滤结构化数据。
索引并发创建:很多数据系统在用户创建索引时需要锁表,一旦锁表,将会阻塞该表的所有查询,从而对线上业务产生不良影响。ProtonBase 引入了并发创建索引的选项,使用户在创建索引时不需要锁表,从而不影响线上业务的正常运行。
ProtonBase 的一个独特之处在于其支持全局二级索引。为了确保索引和数据之间的一致性,系统需要在增删改的时候保证它们具有“原子性”,即数据和索引的变更要么同时成功而且同时可见,要么同时失败,不能存在中间状态。在分布式系统当中,因为一条数据和索引的信息可能存储在不同的节点上,这种保证变得非常有挑战性,必须实现了分布式事务才能做到这点。但是作为用户完全不需要理解里面复杂的实现,这一切对用户都是透明的。
分层存储
用户使用的数据的生命周期往往有一些特点。比如,对大部分业务来说,最新的数据用得最多,随着数据慢慢变老,它也会变得越来越冷,很少有查询需要它。这时如果系统把这些冷的历史数据放到一个更便宜的云存储,比如 S3 中,就能够减少系统的存储成本。

分层存储正是为这个场景设计。ProtonBase 可以通过分层存储把热的实时数据放到高性能的存储,比如 EBS 中,而把冷的历史数据放在低成本的 S3 中。通过这种分层存储的能力,系统能够高效低成本地存储实时数据和历史数据。