大语言模型
方案概述
大语言模型(Large Language Models,简称 LLMs)是一种人工智能技术,利用深度学习算法训练大型神经网络,以理解和生成自然语言文本。这些模型通常基于 Transformer 架构,能够处理和理解大量语言数据。近年来,虽然大语言模型取得了显著进展,但也面临偏见、误解及生成不准确信息等挑战。
RAG(检索增强生成,Retrieval-Augmented Generation)是一种结合信息检索(Retrieval)与文本生成(Generation)的自然语言处理技术。它通过从大规模数据源中检索相关信息,来增强大型语言模型(如 GPT、BERT 等)在处理特定任务时的性能和准确性。
ProtonBase 具备强大的向量检索能力,在 RAG 系统中提供高效的向量存储和检索解决方案,使 RAG 系统能够快速从大规模数据中检索相关信息并提升生成模型的表现。通过这一方案,企业在大语言模型应用场景中可显著提高数据管理与检索效率,为 AI 业务发展奠定坚实基础。
业务挑战
数据时效性差
大模型训练的数据基于特定时间点前,导致知识库受限,无法利用最新数据。
无法访问私有数据 & 缺少专业数据
训练过程中无法使用本地私有数据,且数据可能缺乏特定领域的专业知识。
幻觉
数据过时或缺少相关信息时,生成的内容质量降低。
融合检索
为提升生成质量,可能需要使用多种检索方式召回数据并重排序。若单独部署该流程,系统维护复杂度将增加。
产品能力
强大的向量数据存储与检索功能
ProtonBase 数据库提供高效的向量数据存储与检索能力,Embedding 服务处理的内容向量可无缝更新至数据库。此直接更新机制简化了数据流程管理,提高了效率,尤其适用于快速匹配相似项的应用场景。
融合检索
ProtonBase 支持完整的 SQL 表达能力,可在单一 SQL 查询中进行多种召回计算与汇总,并对多路结果重排序,充分利用引擎性能,简化架构,提升执行效率。
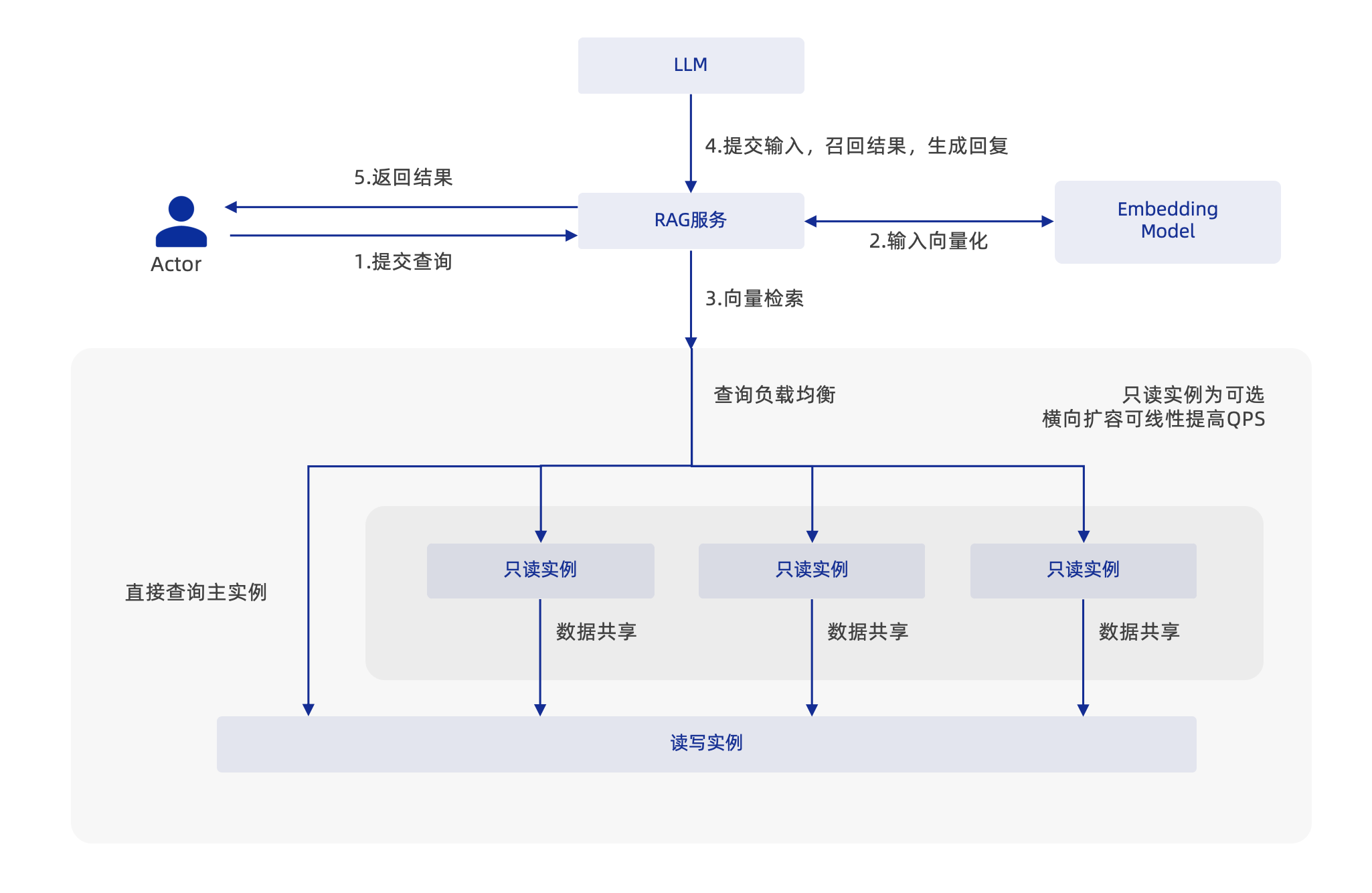
服务能力的横向扩展
ProtonBase 允许一个主实例绑定多个只读从实例,共享同一数据存储但具备独立计算资源。此设计支持快速扩缩容以应对业务波动,提升系统吞吐率,且系统响应速度不受数据复制和移动操作影响。
多功能数据处理能力
ProtonBase 可同时存储向量与标量数据,满足多样化的数据存储需求。标量数据存储能力支持精确数值计算场景,并通过数据同步工具实现与现有 RDS 系统的低延迟同步,保证数据实时性。统一检索简化查询流程,便于用户在复杂场景中获取所需数据。
方案优势
向量标量统一存储,减少冗余
ProtonBase 集成数据库、数据仓库、搜索引擎和向量引擎,提供卓越的查询与分析性能,满足多业务场景需求,避免扩缩容中的不稳定和冗余存储。
极致弹性,秒级扩容
支持秒级在线扩容,且扩容过程服务不中断,性能随计算节点扩展呈线性增长,有效应对流量洪峰。
云上全托管,简化运维
ProtonBase 以全托管形式提供,简化流程、降低运维负担,提高系统稳定性,助力用户专注业务开发。
方案步骤
仅需 4 步即可使用 ProtonBase 实现 RAG:
- 导入:使用 ProtonBase 的数据同步工具,将 RDS 数据、非结构化数据、日志等导入数据库
- 嵌入:将数据预处理为向量,以便进行高效的向量检索。
- 检索:将用户输入向量化并在数据库中查询,召回相关数据记录。
- 生成:将用户输入及召回文档传递给大语言模型,以生成更准确的答案。
嵌入
- 数据管道,进行旁路订阅,向量与处理服务,负责更新向量,参考以下代码;
import psycopg2
it = load_data() # 加载训练数据
with psycopg2.connect('host=... user=... password=... dbname=rag') as conn:# 连接protonbase向量数据库
with conn.cursor() as cursor:
for row in it:
emb = get_embedding(it['content']) # 通过调用embedding API,将数据向量化
row_id = row['id']
cursor.update('UPDATE table_name SET emb=%s WHERE id = %s', (emb, row_id)) # 更新已同步的数据记录
conn.commit() # commit写入

检索 & 生成
import psycopg2
def handle_request(req):
level = req.data['level'] # 标量过滤条件
user_input = req.data['user_input']
emb = get_embedding(user_input) # 将用户输入向量化
with psycopg2.connect('') as conn: # 连接向量数据库
with conn.cursor() as cursor:
sql = f'''select content from table_name
WHERE level = %s /*根据标量过滤数据*/
ORDER BY emb <=> %s /*进行向量排序*/
limit 100 /*召回TOP 100结果*/
'''
cursor.execute(sql, (level, emb)) # 执行向量、标量联合检索查询
relative_contents = [row[0] for row in cursor] # 根据向量,召回所有相关的数据内容
response = llm_generate(user_input, relative_contents) # 调用大语言模型,生成回复
return response