ProtonBase 核心能力:增量物化视图

1. 引言
在当今实时数据处理和流式计算的大潮中,多流 Join 操作成为了一个非常重要且具有挑战性的场景。无论是在广告投放、金融风控,还是物联网数据监控中,不同数据源之间的关联分析都扮演着举足轻重的角色。随着数据量的激增,如何在保证实时性和准确性的前提下,实现多个数据流的高效关联,已经成为技术架构师和开发者必须面对的关键问题。
目前,Apache Flink 作为领先的流处理框架,广泛应用于实时数据处理任务中。Flink 提供了基于事件驱动和状态管理的多流 Join 解决方案,通常采用逐级双流 Join 的方式逐步将多个流关联起来。然而,这种做法在面对多个流(例如 5 个或更多表的 Join)时,会导致状态数据量呈指数级增长。换句话说,要保证数据正确性,Flink 必须维护大量状态,否则就无法在 Join 时正确关联到每一条数据;而如果为了节省状态,选择了 Lookup Join 或者通过减少 TTL 等手段来降低状态压力,则不可避免地会牺牲数据的一致性和实时性。
为了解决这一矛盾,ProtonBase 提出了一种解决方案——增量物化视图。该方案通过将每张表的数据本身作为全量状态存储,并在每次更新时仅计算增量(delta),从而避免了逐级双流 Join 中每层都保存大量中间结果的状态爆炸问题。本文将详细介绍 Flink 的现有做法及其缺陷、ProtonBase 的解决方案及优势,并通过一个 Demo 演示增量计算过程,证明 ProtonBase 在数据一致性和正确性方面的优势。
2. Flink 多流 Join 的实现方式与缺陷
在 Flink 中,多流 Join 通常采用逐级双流 Join 的方式,即先将两个流进行 Join,再将中间结果与下一个流 Join,从而逐步实现多流关联。下面详细介绍这种做法的实现方式及其主要缺陷,同时重点说明为何必须维护大量状态。
2.1 逐级双流 Join 的实现方式与状态存储的必要性
-
1. 基础原理与数据到达时序问题
-
在实时数据处理中,数据通常会异步到达,顺序和时间存在不确定性。例如,当我们对两个流进行 Left Join(例如表 L 和表 R),存在以下情况:
- 数据延迟/乱序:可能表 L 的数据先到,而表 R 的数据稍后到达。此时,为了确保最终 Join 结果的正确性,Flink 必须先输出类似 (L, null) 的临时结果,并将 L 的数据存入状态中等待 R 的数据到来。
- 当 R 的数据到达后,Flink 需要查找状态(State) 中存储的 L 数据,然后撤回之前输出的 (L, null) 结果,并生成正确的 (L, R) 输出。这就要求系统必须维护状态来保存所有等待匹配的事件,以便后续进行正确的关联计算。
-
-
2. 逐级双流 Join 的扩展与状态累积
-
在多流 Join 场景下,Flink 采用逐级双流 Join 的方式,以 5 个表 join 为例:
- 原表 A
- 原表 B
- (A join B) join C
- ((A join B) join C) join D
- (((A join B) join C) join D) join E
-
在这种结构中,每次 Join 操作都需要保存相应的中间结果。实际中,由于 Join 操作通常基于等值匹配,各表数据并不会无限复制,而是按一定比例参与后续 Join。一般来说,可以观察到如下状态存储趋势:
- 表 A 和表 B 在第一步 Join 后,通常各自保留一份匹配结果;
- 当结果与表 C 进行 Join 时,每个原始记录大致会在中间结果中重复存储几次;
- 后续与表 D 和表 E 的 Join 则进一步降低了重复率,最终可能表现为:
- 表 A:大约存储 5 份
- 表 B:大约存储 5 份
- 表 C:大约存储 3 份
- 表 D:大约存储 2 份
- 表 E:1 份
-
这种累积效应使得整个逐级双流 Join 过程中状态量的增长大致呈现平方级别,虽然不会无限增大,但这种规模在实际场景下已经相当可观,对系统资源提出了较高的要求。
-
3. 为什么必须维护状态
- 处理异步到达与乱序:由于数据到达时间的不一致,只有通过维护状态,才能在后续到达的数据中找到匹配项,避免因数据缺失而导致 Join 结果错误。
- 确保数据正确性:无论数据是否延迟到达,为了在后续撤回 (L, null) 并生成正确的 (L, R) 结果,系统必须保存所有未匹配的事件和中间结果。这种完整状态存储是实现精确事件匹配和正确 Join 的必要条件。
2.2 Flink 做法的主要缺陷
-
-
大量状态要求
- 正确性保障:为确保 Join 过程正确处理所有数据,Flink 必须在状态中存储所有未匹配事件和中间结果,这就要求必须付出大量的存储资源。
- 资源消耗高:这种做法直接导致内存和存储资源的消耗急剧增加,当在数据量大或 Join 层级较深的场景中,这种情况尤其严重。
-
-
-
状态膨胀风险
- 尽管实际中状态增长大致呈平方级别,但随着 Join 层级的增加,状态量依然会逐步累积。如果不进行有效管理,可能会对系统性能和容错能力构成挑战。
- 状态量巨大不仅会增加资源消耗,还会使得状态管理、故障恢复和错误追溯变得异常复杂。
-
-
- 为省状态牺牲一致性
-
为了降低状态压力,有些场景会采用 Lookup Join(也称为维表 Join)或缩短状态 TTL 来清理状态。这些方法虽然能有效降低资源消耗,但不可避免地会引入数据不一致性的问题。下面详细说明这些方法与传统逐级双流 Join 的区别以及导致不一致性的原因:
- 维表 Join(Lookup Join)的特点与差异
- 依赖外部存储:维表 Join 通常不在流处理中直接维护大规模的中间状态,而是将较为静态或更新较慢的关联数据存储在外部系统中(如关系型数据库、NoSQL 存储或内存缓存)。在实时计算时,主流中的数据通过查找这些外部存储的数据来完成 Join 操作。
- 数据同步延迟:由于外部存储的数据更新频率可能不及流数据,或者外部系统响应存在延迟,这就会导致实时查询时,外部数据与流数据之间存在时间差,进而出现 Join 结果滞后或不完整的情况。
- 调试复杂性:外部存储引入了额外的依赖,一旦出现数据不一致的问题,难以确定问题是出在流计算本身还是外部存储的数据同步问题,调试起来相对更加困难。
- 维表 Join 不一致问题:在高并发或数据量突增的场景下,外部存储可能出现压力过大或临时不可用的情况,导致部分查询失败或返回错误结果,从而加剧数据不一致性。
- 缩短 TTL 的影响
- 过早清理状态:通过缩短状态的 TTL,可以减少状态在系统中的存储时间,从而降低资源占用。然而,TTL 清理机制是基于时间的,当数据在 TTL 过期前未能匹配到后续数据时,系统会将其清理掉。
- 导致数据丢失:如果某些未匹配的中间结果被提前清理,而后续数据原本应该和这些结果进行匹配,则最终的 Join 结果就会出现缺失,破坏数据的一致性。
- 维表 Join(Lookup Join)的特点与差异
-
总结对比
- 传统逐级双流 Join:依赖内部状态存储所有中间结果,虽然状态累积会较大(呈现平方级别增长),但能确保每个数据匹配过程的正确性和实时更新,保证了数据一致性。
- Lookup Join 和缩短 TTL:通过外部关联和快速状态清理,降低了内存和存储压力,但引入了外部系统延迟、数据同步问题以及数据丢失风险,从而导致 Join 结果可能出现不一致或滞后。
综上所述,Flink 的逐级双流 Join 模式在面对数据到达不一致(例如先出现 (L, null) 再撤回、再补全 (L, R))时,必须通过大量状态存储来确保数据正确性和完整性。但这也导致了状态膨胀和资源消耗问题,并迫使部分场景不得不在正确性与状态资源之间做出权衡。接下来的部分中,我们将介绍 ProtonBase 如何通过增量物化视图技术,从根本上解决这一矛盾。
3. ProtonBase 的增量物化视图解决方案
针对 Flink 面临的状态爆炸与数据一致性之间的矛盾,ProtonBase 提出了增量物化视图(Incremental Materialized View) 的解决方案,其核心思想可以归纳为以下几点:
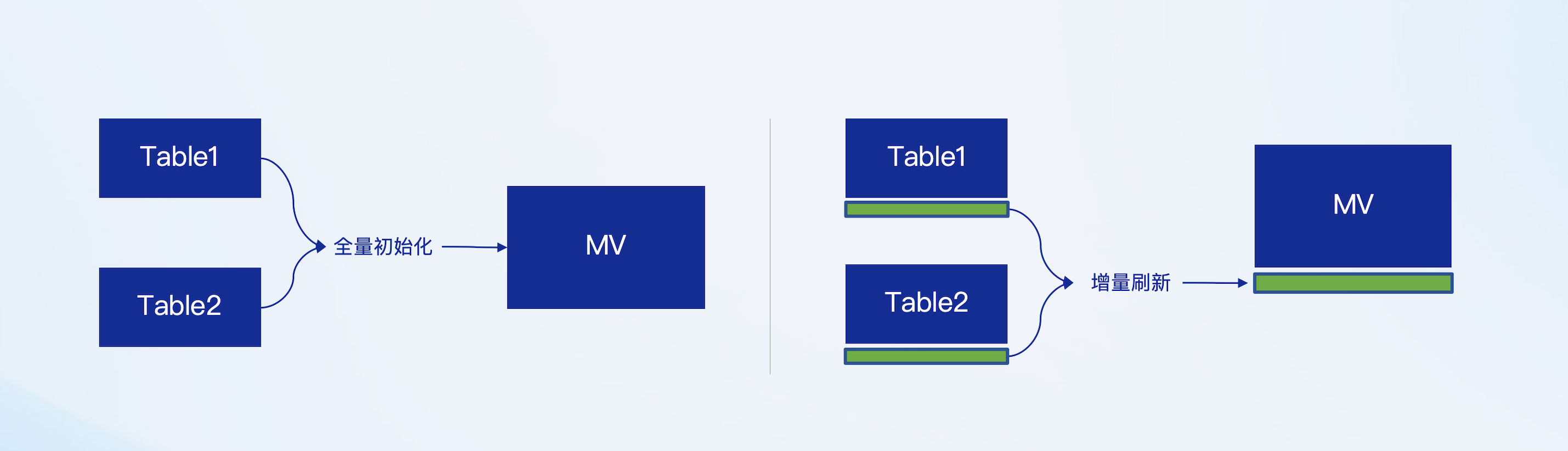
-
全量状态存储: 在 ProtonBase 中,每张表的数据本身就作为全量状态存储下来。这意味着系统从一开始就完整保存了每个表的所有数据,而不必在 Join 时额外构造庞大的中间状态。通过这种方式,ProtonBase 避免了在逐级双流 Join 过程中不断累积和保存海量中间结果的问题,从而大大降低了状态的规模。
-
增量计算 Delta: 当一张表发生更新时(例如表 L 产生更新),ProtonBase 并不会触发全量 Join,而是仅计算更新部分的增量(delta)。这种基于 delta 的增量计算方式极大地减少了需要处理的数据量,具体包括以下两个场景:
- 场景 A:如果表 L 更新,而表 R 未更新,此时系统会生成 ,然后利用 与表 R 的全量数据进行 Join,产生新的结果增量,并将这些增量更新写入到物化视图中。
- 场景 B:当表 R 后续也有更新时,会生成,同样利用与表 L 的全量数据进行 Join,再次更新物化视图。
这种增量更新机制使得每一次 Join 操作只需要处理变化的数据,而非重新计算全量数据,从而大幅降低了状态存储的需求。
这种设计思路带来的优势如下:
-
-
避免状态爆炸
-
传统逐级双流 Join 的问题
- 在传统的 Flink 逐级双流 Join 模型中,每个 Join 操作都需要保存左右两侧所有未匹配的事件和中间结果。状态量呈约平方级增长,不仅消耗大量内存和存储资源,而且在大规模数据场景下极易成为性能瓶颈。
-
ProtonBase 的解决方案
- ProtonBase 采用了增量计算的方式,只针对更新部分计算 delta。也就是说,每次只处理新增或变更的数据,而不是重新计算全量 Join。通过这种方式:
- 状态存储需求大幅降低:系统仅需要存储全量状态和每次更新的 delta,而不必保存所有中间计算结果。
- 高效更新:在数据更新时,只对变更部分进行处理,从而避免了在 Join 过程中状态数据呈指数级增长的风险。
- ProtonBase 采用了增量计算的方式,只针对更新部分计算 delta。也就是说,每次只处理新增或变更的数据,而不是重新计算全量 Join。通过这种方式:
-
-
-
保证数据一致性
- 全量状态与精确更新
-
ProtonBase 的核心在于将每张表的数据本身作为全量状态进行存储,再通过精确的增量更新来计算 Join 结果。这一策略确保了:
-
每次更新都有明确记录:无论是表 L 还是表 R 的更新,系统都会生成对应的 delta,并利用全量数据进行 Join,从而保证了更新过程的透明性和可追溯性。
-
数据一致性得到严格保证:最终的物化视图(MV)始终与全量数据保持同步,即使面对数据延迟、乱序等情况,也能通过增量更新撤回临时结果(例如 (L, null))并生成正确的最终结果(例如 (L, R))。
-
- 相较于维表 Join(Lookup Join)
- 虽然 Lookup Join 可以节省状态,但由于其依赖外部存储进行关联,往往会引入额外的延迟和数据同步问题,加剧数据不一致的风险,同时也使得问题的调试变得更加困难。ProtonBase 内部维护全量状态和详细的 delta 更新记录,从而确保数据更新过程的完整性和一致性。
-
-
- 良好的扩展性
- 处理多流 Join 的能力
- 传统逐级双流 Join 模型在面对多个流(如 5 个或更多表的 Join)时,由于中间状态不断叠加,会迅速超出系统资源承受能力。而 ProtonBase 的增量物化视图方案,每次仅对增量部分进行处理,避免了累积多层中间结果的问题。
- 实际扩展能力
- 实际测试表明,ProtonBase 的方案在支持 18 层 的 Join 时,仍可以表现优异,这充分展示了其在状态管理和多流扩展性方面的强大能力。系统在面对复杂 Join 逻辑时,依然能够保持高效更新和实时响应。
-
-
降低调试复杂性
-
传统维表 Join 的挑战
- 尽管维表 Join(Lookup Join)在一定程度上可以降低内部状态的存储压力,但其依赖外部存储的特性会引入多种问题:
- 数据不一致性:外部存储与流数据之间存在同步延迟,可能导致 Join 结果不完整或滞后。
- 调试难度高:外部系统的介入使得错误追踪和数据溯源变得非常困难,尤其是在出现数据丢失或错误匹配时,很难确定问题究竟出在流计算部分还是外部存储中。
- 尽管维表 Join(Lookup Join)在一定程度上可以降低内部状态的存储压力,但其依赖外部存储的特性会引入多种问题:
-
ProtonBase 的优势
- 通过内部维护完整的全量状态以及每次更新的详细 delta 记录,ProtonBase 使得错误排查和数据溯源更加透明和可控:
- 清晰的更新记录:每次数据变更都被精确记录,可以追踪到每一次 delta 的计算过程。
- 便于调试:当出现问题时,开发者可以通过详细的增量更新日志,快速定位到问题所在,从而大幅降低调试复杂性。
- 通过内部维护完整的全量状态以及每次更新的详细 delta 记录,ProtonBase 使得错误排查和数据溯源更加透明和可控:
-
综上所述,ProtonBase 通过采用全量状态存储和基于 delta 的增量更新策略,既避免了传统逐级双流 Join 的状态爆炸问题,又保证了数据的一致性和正确性,同时展现出极强的扩展性和调试友好性。这种设计思路为复杂实时数据处理场景提供了一种高效、可靠的解决方案。接下来的章节,我们将通过一个 Demo 进一步验证这一方案在数据一致性和正确性方面的优势。
4. Demo:验证 ProtonBase 增量物化视图的数据一致性和调试便捷性
下面是完整的 SQL Demo 脚本,便于理解和调试。此 Demo 展示了两个关键点:
- 数据一致性优势:通过增量物化视图,能够自动撤回临时结果,保证 (L, null) 最终更新为 (L, R);
- 调试方便性:所有基础数据保留在原表中,开发者可直接查询原表、全量物化视图与增量物化视图进行对比;同时,利用时间旅行功能,可以回溯到刷新前的快照状态,便于调试历史数据一致性问题。
下面按照 5 个步骤展示整个流程,其中利用 psql 的 \gset 命令记录快照时间(纳秒级),再通过时间旅行语法验证历史状态。
Step 0:清理环境(可选)
DROP MATERIALIZED VIEW IF EXISTS MV_full;
DROP MATERIALIZED VIEW IF EXISTS MV_inc;
DROP TABLE IF EXISTS L;
DROP TABLE IF EXISTS R;
Step 1:基准数据 —— 建立初始匹配数据
目标:构建最初的基础环境,创建表 L、R,并插入初始数据,建立全量物化视图 MV_full(全量刷新)和增量物化视图 MV_inc(增量刷新),使得初始状态下 MV 显示正确的 Join 结果。
-- 创建基础表 L 和 R
CREATE TABLE L (
id INT PRIMARY KEY,
value VARCHAR(100)
);
CREATE TABLE R (
id INT PRIMARY KEY,
value VARCHAR(100)
);
-- 插入初始数据,确保 id=1 在 L 和 R 中均有匹配
INSERT INTO L (id, value) VALUES (1, 'L1');
INSERT INTO R (id, value) VALUES (1, 'R1');
接下来,创建两个物化视图:
- MV_full:全量物化视图(默认全量刷新)
- MV_inc:增量物化视图(使用增量刷新模式)
-- 创建全量物化视图(默认全量刷新)
CREATE MATERIALIZED VIEW MV_full AS
SELECT L.id, L.value AS L_value, R.value AS R_value
FROM L LEFT JOIN R ON L.id = R.id;
-- 创建增量物化视图(增量刷新模式)
CREATE MATERIALIZED VIEW MV_inc WITH (refresh_mode='incremental') AS
SELECT L.id, L.value AS L_value, R.value AS R_value
FROM L LEFT JOIN R ON L.id = R.id;
查询初始结果(无须刷新,新建时已生成初始数据):
SELECT * FROM MV_full;
SELECT * FROM MV_inc;
预期结果:
(1, 'L1', 'R1')
Step 2:引入不匹配数据,产生 (L, null) 状态
目标:向表 L 插入新记录(例如 id=2),由于表 R 中没有匹配数据,直接 JOIN 后显示 (L, null)。
-- 向表 L 插入一条新记录 id=2(R 中尚无匹配)
INSERT INTO L (id, value) VALUES (2, 'L2');
刷新物化视图以使更新生效:
REFRESH MATERIALIZED VIEW MV_full;
REFRESH MATERIALIZED VIEW MV_inc;
查询更新后的视图结果:
SELECT * FROM MV_full;
SELECT * FROM MV_inc;
预期结果:
- 对于 id=1:
(1, 'L1', 'R1')- 对于 id=2:
(2, 'L2', NULL)- 此时,物化视图正确记录了新增数据未匹配的情况 —— 即 (L, null)。
Step 3:补全匹配数据并引入额外数据,同时记录快照时间
目标:为之前 (L, null) 的记录补充匹配数据,并模拟额外数据更新,同时在刷新 MV 前记录快照时间,以便后续回溯调试。
-- 向表 R 插入与 id=2 匹配的数据,补全 (L, null) → (L, R)
INSERT INTO R (id, value) VALUES (2, 'R2');
-- 同时,为模拟额外更新,向表 L 插入新记录 id=3
INSERT INTO L (id, value) VALUES (3, 'L3');
记录当前系统时间(纳秒级)
-- 在刷新 MV 前记录当前系统时间(纳秒级)作为快照
SELECT (EXTRACT(EPOCH FROM CURRENT_TIMESTAMP) * 1000000000)::bigint AS snap_ts;
\gset
再次刷新物化视图:
REFRESH MATERIALIZED VIEW MV_full;
REFRESH MATERIALIZED VIEW MV_inc;
查询刷新后的视图结果:
SELECT * FROM MV_full;
SELECT * FROM MV_inc;
预期结果:
(1, 'L1', 'R1')(2, 'L2', 'R2')(3, 'L3', NULL)- 这样,原先 (L, null) 的结果已自动更新为 (L, R),证明 ProtonBase 的增量刷新机制能够自动撤回临时结果,确保数据一致性。与 Flink 的 Lookup Join 相比,这种全量与增量对比更新的机制能更好地保证正确性。
Step 4:继续向原表插入新数据
目标:模拟实时环境中原表数据持续更新,插入新数据(例如 id=4),使得直接查询基础表 JOIN 结果与 MV 刷新时的状态不一致。
-- 向表 L 和 R 插入新数据(例如 id=4),模拟后续数据更新
INSERT INTO L (id, value) VALUES (4, 'L4_new');
INSERT INTO R (id, value) VALUES (4, 'R4_new');
-- 如果这个时候发现业务不一致,直接查询原表是不方便调试的,因为结果已经变了
SELECT * FROM MV_inc;
-- 直接查询当前基础表的 JOIN 结果
SELECT L.id, L.value AS L_value, R.value AS R_value
FROM L LEFT JOIN R ON L.id = R.id;
预期结果:会显示
(1, 'L1', 'R1')(2, 'L2', 'R2')(3, 'L3', NULL)(4, 'L4_new', 'R4_new')- 通过向原表插入新数据,我们模拟了实时数据不断更新的场景。此时,直接查询当前基础表的 JOIN 结果会包含最新数据(例如 id=4),从而与之前 MV 刷新时的状态产生差异。影响调试
Step 5:利用时间旅行调试验证数据一致性(调试方便)
目标:利用时间旅行回溯到 Step 3 刷新前记录的快照时间,验证当时基础表数据状态与 MV 刷新结果一致,从而证明数据一致性优势与调试方便性。
-- 使用时间旅行查询,在记录的快照时间查询基础表 L 的状态
SELECT * FROM L FOR SYSTEM_TIME AS OF :'snap_ts';
-- 使用时间旅行查询,在记录的快照时间查询基础表 R 的状态
SELECT * FROM R FOR SYSTEM_TIME AS OF :'snap_ts';
-- 查询MV
SELECT * FROM MV_inc;
-- 基于快照时刻的数据,再执行 LEFT JOIN 得到当时的匹配结果
SELECT L.id, L.value AS L_value, R.value AS R_value
FROM L FOR SYSTEM_TIME AS OF :'snap_ts'
LEFT JOIN R FOR SYSTEM_TIME AS OF :'snap_ts'
ON L.id = R.id;
预期结果:应显示
(1, 'L1', 'R1')(2, 'L2', 'R2')(3, 'L3', NULL)- 通过时间旅行查询,我们回溯到刷新前记录的快照时刻,重新计算当时的 JOIN 结果,并发现与 MV 刷新时的数据一致。这证明了 ProtonBase 的增量刷新机制能够自动将 (L, null) 更新为 (L, R),确保数据一致性;同时,利用时间旅行回溯历史状态,极大地简化了调试过程,相较于 Flink 的 Lookup Join 方式更直观可靠。
小结
通过上述 Demo 的流程,我们展示了 ProtonBase 增量物化视图在实时数据处理中的两大优势:
-
-
高一致性
- 即使初始输出 (L, null)(由于新增数据无匹配),在后续新增匹配数据后,刷新视图能自动将其更新为 (L, R),确保最终结果与全量 JOIN 保持一致。
- 这种全量状态存储加上精确的增量更新机制,确保了数据一致性,而这是 Flink 的 Lookup Join 难以实现的,因为后者容易受到外部数据同步延迟和一致性问题的影响。
-
-
-
调试方便
- 所有原始数据均保留在基础表 L 和 R 中,开发者可以随时通过标准 SQL 查询对比全量 JOIN 结果与物化视图数据,从而直观了解每次数据更新的效果。
- 利用明确的刷新命令(REFRESH MATERIALIZED VIEW)和时间旅行功能(例如使用
FOR SYSTEM_TIME AS OF语法),可以记录并回溯到特定快照时间,验证在 MV 刷新时的数据状态是否正确。这种方式即使在原表数据持续更新的情况下,也能精确还原历史状态,大大降低了调试和问题定位的难度。
-
这套 Demo 充分展示了 ProtonBase 增量物化视图方案,不仅能自动撤回临时结果、保证数据一致性,还通过时间旅行特性实现了便捷的历史数据回溯,使调试过程更加直观可靠,从而在实时计算场景中展现出明显优于传统 Flink 维表 Join 方案优势。
5. 总结与展望
本文详细讨论了实时多流 Join 场景中数据一致性和状态管理面临的挑战,并展示了 ProtonBase 增量物化视图解决方案如何应对这些问题。传统方案为了保证数据一致性,往往需要用大量状态换取正确性,而这在多流 Join 场景下会导致状态呈平方级增长,严重消耗资源,并增加调试复杂性。相比之下,ProtonBase 采用全量状态存储与增量更新相结合的方式,既能保证数据一致性,又避免了状态爆炸问题,同时实现了类似 Flink 的实时计算效果,具备较低延迟的更新能力。
5.1 数据一致性与状态管理
-
传统方法的挑战
- 在 Flink 的逐级双流 Join 或 Lookup Join 模型中,为确保每次 Join 的正确匹配,系统必须保存所有未匹配事件和中间结果。当数据存在异步到达或乱序时,这种状态保存才能保证最终 Join 结果正确,但会导致状态存储量呈平方级增长。
- Flink Lookup Join 依赖外部维表,容易因数据同步延迟产生不一致问题,同时调试起来较为复杂。
-
ProtonBase 的突破
- 全量状态 + 增量更新:ProtonBase 将每张表的数据作为全量状态存储,并在更新时仅计算增量(delta),既保证了数据一致性,又避免了状态累积的指数级爆炸。
- 自动撤回临时结果:即使最初输出了 (L, null) 等临时结果,后续补充匹配数据后,通过刷新视图自动更新为正确的 (L, R)。
- 实时计算能力:这种增量刷新机制使得 ProtonBase 能够实现类似 Flink 的实时计算效果,快速响应数据更新,同时降低了对计算资源的要求。
5.2 调试与维护便捷性
- 自包含的数据透明性 所有基础数据均保留在原表中(如 L 和 R),开发者可以直接通过 SQL 对比原始数据、全量物化视图与增量物化视图的结果,直观了解每个数据更新阶段的状态;同时,利用时间旅行查询,可以回溯到特定快照时刻,验证历史数据状态,进一步辅助调试。
- 明确的刷新与时间回溯机制
利用
REFRESH MATERIALIZED VIEW命令,开发者能够精确控制视图刷新过程,并对比刷新前后的结果,便于快速定位和调试问题;结合时间旅行查询,在原表数据不断更新的情况下仍能还原历史快照,极大地降低了调试复杂度。与 Flink Lookup Join 依赖外部系统相比,这种方式更加直观、便捷。
总结而言,ProtonBase的增量物化视图方案为实时多流 Join 提供了一条高效、可靠且调试友好的解决路径。 这一方案不仅在数据一致性上明显优于传统 Flink 维表 Join,且通过增量更新实现了类似 Flink 的实时计算效果,同时显著避免了状态爆炸问题。所有基础数据均保留在内部,使得调试过程直观透明,降低了系统维护的复杂性。